- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case AskWhy Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research Research Tools and Apps

Analytical Research: What is it, Importance + Examples

Finding knowledge is a loose translation of the word “research.” It’s a systematic and scientific way of researching a particular subject. As a result, research is a form of scientific investigation that seeks to learn more. Analytical research is one of them.
Any kind of research is a way to learn new things. In this research, data and other pertinent information about a project are assembled; after the information is gathered and assessed, the sources are used to support a notion or prove a hypothesis.
An individual can successfully draw out minor facts to make more significant conclusions about the subject matter by using critical thinking abilities (a technique of thinking that entails identifying a claim or assumption and determining whether it is accurate or untrue).
What is analytical research?
This particular kind of research calls for using critical thinking abilities and assessing data and information pertinent to the project at hand.
Determines the causal connections between two or more variables. The analytical study aims to identify the causes and mechanisms underlying the trade deficit’s movement throughout a given period.
It is used by various professionals, including psychologists, doctors, and students, to identify the most pertinent material during investigations. One learns crucial information from analytical research that helps them contribute fresh concepts to the work they are producing.
Some researchers perform it to uncover information that supports ongoing research to strengthen the validity of their findings. Other scholars engage in analytical research to generate fresh perspectives on the subject.
Various approaches to performing research include literary analysis, Gap analysis , general public surveys, clinical trials, and meta-analysis.
Importance of analytical research
The goal of analytical research is to develop new ideas that are more believable by combining numerous minute details.
The analytical investigation is what explains why a claim should be trusted. Finding out why something occurs is complex. You need to be able to evaluate information critically and think critically.
This kind of information aids in proving the validity of a theory or supporting a hypothesis. It assists in recognizing a claim and determining whether it is true.
Analytical kind of research is valuable to many people, including students, psychologists, marketers, and others. It aids in determining which advertising initiatives within a firm perform best. In the meantime, medical research and research design determine how well a particular treatment does.
Thus, analytical research can help people achieve their goals while saving lives and money.
Methods of Conducting Analytical Research
Analytical research is the process of gathering, analyzing, and interpreting information to make inferences and reach conclusions. Depending on the purpose of the research and the data you have access to, you can conduct analytical research using a variety of methods. Here are a few typical approaches:
Quantitative research
Numerical data are gathered and analyzed using this method. Statistical methods are then used to analyze the information, which is often collected using surveys, experiments, or pre-existing datasets. Results from quantitative research can be measured, compared, and generalized numerically.
Qualitative research
In contrast to quantitative research, qualitative research focuses on collecting non-numerical information. It gathers detailed information using techniques like interviews, focus groups, observations, or content research. Understanding social phenomena, exploring experiences, and revealing underlying meanings and motivations are all goals of qualitative research.
Mixed methods research
This strategy combines quantitative and qualitative methodologies to grasp a research problem thoroughly. Mixed methods research often entails gathering and evaluating both numerical and non-numerical data, integrating the results, and offering a more comprehensive viewpoint on the research issue.
Experimental research
Experimental research is frequently employed in scientific trials and investigations to establish causal links between variables. This approach entails modifying variables in a controlled environment to identify cause-and-effect connections. Researchers randomly divide volunteers into several groups, provide various interventions or treatments, and track the results.
Observational research
With this approach, behaviors or occurrences are observed and methodically recorded without any outside interference or variable data manipulation . Both controlled surroundings and naturalistic settings can be used for observational research . It offers useful insights into behaviors that occur in the actual world and enables researchers to explore events as they naturally occur.
Case study research
This approach entails thorough research of a single case or a small group of related cases. Case-control studies frequently include a variety of information sources, including observations, records, and interviews. They offer rich, in-depth insights and are particularly helpful for researching complex phenomena in practical settings.
Secondary data analysis
Examining secondary information is time and money-efficient, enabling researchers to explore new research issues or confirm prior findings. With this approach, researchers examine previously gathered information for a different reason. Information from earlier cohort studies, accessible databases, or corporate documents may be included in this.
Content analysis
Content research is frequently employed in social sciences, media observational studies, and cross-sectional studies. This approach systematically examines the content of texts, including media, speeches, and written documents. Themes, patterns, or keywords are found and categorized by researchers to make inferences about the content.
Depending on your research objectives, the resources at your disposal, and the type of data you wish to analyze, selecting the most appropriate approach or combination of methodologies is crucial to conducting analytical research.
Examples of analytical research
Analytical research takes a unique measurement. Instead, you would consider the causes and changes to the trade imbalance. Detailed statistics and statistical checks help guarantee that the results are significant.
For example, it can look into why the value of the Japanese Yen has decreased. This is so that an analytical study can consider “how” and “why” questions.
Another example is that someone might conduct analytical research to identify a study’s gap. It presents a fresh perspective on your data. Therefore, it aids in supporting or refuting notions.
Descriptive vs analytical research
Here are the key differences between descriptive research and analytical research:
| Aspect | Descriptive Research | Analytical Research |
| Objective | Describe and document characteristics or phenomena. | Analyze and interpret data to understand relationships or causality. |
| Focus | “What” questions | “Why” and “How” questions |
| Data Analysis | Summarizing information | Statistical research, hypothesis testing, qualitative research |
| Goal | Provide an accurate and comprehensive description | Gain insights, make inferences, provide explanations or predictions |
| Causal Relationships | Not the primary focus | Examining underlying factors, causes, or effects |
| Examples | Surveys, observations, case-control study, content analysis | Experiments, statistical research, qualitative analysis |
The study of cause and effect makes extensive use of analytical research. It benefits from numerous academic disciplines, including marketing, health, and psychology, because it offers more conclusive information for addressing research issues.
QuestionPro offers solutions for every issue and industry, making it more than just survey software. For handling data, we also have systems like our InsightsHub research library.
You may make crucial decisions quickly while using QuestionPro to understand your clients and other study subjects better. Make use of the possibilities of the enterprise-grade research suite right away!
LEARN MORE FREE TRIAL
MORE LIKE THIS

A guide to conducting agile qualitative research for rapid insights with Digsite
Sep 11, 2024

Was The Experience Memorable? — Tuesday CX Thoughts
Sep 10, 2024

What Does a Data Analyst Do? Skills, Tools & Tips
Sep 9, 2024

Best Gallup Access Alternatives & Competitors in 2024
Sep 6, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Tuesday CX Thoughts (TCXT)
- Uncategorized
- What’s Coming Up
- Workforce Intelligence

Analytical Modeling: Turning Complex Data into Simple Solutions
Updated: January 28, 2024 by iSixSigma Staff
Not everything in business is quantifiable, but most of it is. Understanding the relationships between dozens of different factors and forces influencing a specific outcome can seem impossible, but it’s not. Analytical modeling is an effective and reliable technique for turning a mess of different variables and conditions into information you can actually use to make decisions.
Overview: What is analytical modeling?
Analytical modeling is a mathematical approach to business analysis that uses complex calculations that often involve numerous variables and factors. This type of analysis can be a powerful tool when seeking solutions to specific problems when used with proper technique and care.
3 benefits of analytical modeling
It’s hard to overstate the value of strong analytics. Mathematical analysis is useful at any scale and for almost every area of business management.
1. Data-driven decisions
The primary benefit of leveraging analytical modeling is the security of making data-driven decisions. Leaders don’t have to take a shot in the dark. They can use analytics to accurately define problems , develop solutions and anticipate outcomes.
2. Logical information structure
Analytical modeling is all about relating and structuring information in a sensible way. This means you can use the results to trace general outcomes to specific sources.
3. Can be shared and improved
The objective nature of analytical modeling makes it a perfect way to establish a common foundation for discussion among a diverse group. Rather than trying to get everyone on the same page through personal and subjective theorizing, using analytical data establishes a singular framework for universal reference within an organization.
Why is analytical modeling important to understand?
Like any other business practice, it’s important to understand this kind of analysis so you know what it can and can’t do. Even though it’s a powerful tool in the right hands, it’s not a magic solution that’s guaranteed to fix your problems.
Information requires interpretation
Information can be invaluable or completely worthless depending on how you use it. You should always carefully examine the factors and implications of the data in question before basing major decisions on it.
Analytics needs good data
Accurate, complete and relevant information are essential for a useful outcome. If poor data is put into a model, poor results will come out. Ensuring quality of data collection techniques is just as important as the modeling itself.
Various applications and approaches
Analytical modeling tends to focus on specific issues, questions or problems. There are several different types of models that can be used, which means you need to figure out the one that best fits each situation.
An industry example of analytical modeling
A barbecue restaurant serves customers every day of the week from lunch through dinner. To increase overall profit, management wants to reduce losses from waste and cut down on missed sales. Since they need to start preparing meat days in advance and any leftovers are discarded, the establishment needs to find a way to accurately predict how many customers they will have each day.
The restaurant hires outside contractors to create a predictive analytics model to address this need. The modelers examine various relevant factors, including historical customer attendance in previous weeks, weather predictions and upcoming specials or events of nearby restaurants. They create an initial model and start comparing actual results against predicted results until they’ve reached 90 percent accuracy, which is enough to meet the restaurant’s goals.
3 best practices when thinking about analytical modeling
Think about analytical modeling as a starting point for decisions and a tool that can be continually improved as you use it.
1. Start with a goal
Analytical modeling can’t answer a question that isn’t asked. It’s easy to make the mistake of looking for answers or patterns in general data. This kind of modeling is best used by created calculations to answer a specific initial question, like: “How can we turn more visitors into customers?” or “How can we make this process less wasteful.”
2. Continue to refine parameters
Think of the first model as a rough draft. Once you have an initial model delivering results, it’s important to compare it to reality and find ways to make the results even better.
3. Be consistent
Don’t just turn to analytics when faced with an urgent problem. If you make data mining and analysis a part of your daily operations, you’ll be in a much better position to actually leverage this strategy when the time comes.
Frequently Asked Questions (FAQ) about analytical modeling
What are the common forms of analytical models.
There are four main types of models: descriptive, diagnostic, predictive and prescriptive. The right one to use depends on the kind of question you need an answer to.
How do you make an analytical model?
Modeling requires access to a full set of relevant data points, relationship conditions and project objectives. For example, when trying to predict the outcome of a certain situation, modelers need to account for every factor that can impact this outcome and understand how each one of those factors influences the results as well as other variables in the calculation in a quantifiable way.
What is the purpose of analytical models?
The purpose of analytical modeling is to make sense of a process or situation that has too many variables to estimate accurately. It’s particularly important when dealing with larger operations and processes.
Managing with models
Companies survived for hundreds of years without computing technology to help them do complex modeling. However, that doesn’t mean you will be fine without it. The data revolution has already happened and the capabilities it offers companies can’t be ignored. Business leaders in every industry should be moving modeling to the center of their management practices if they are serious about growing in the years ahead.
About the Author

iSixSigma Staff
Understanding and solving intractable resource governance problems.
- Conferences and Talks
- Exploring models of electronic wastes governance in the United States and Mexico: Recycling, risk and environmental justice
- The Collaborative Resource Governance Lab (CoReGovLab)
- Water Conflicts in Mexico: A Multi-Method Approach
- Past projects
- Publications and scholarly output
- Research Interests
- Higher education and academia
- Public administration, public policy and public management research
- Research-oriented blog posts
- Stuff about research methods
- Research trajectory
- Publications
- Developing a Writing Practice
- Outlining Papers
- Publishing strategies
- Writing a book manuscript
- Writing a research paper, book chapter or dissertation/thesis chapter
- Everything Notebook
- Literature Reviews
- Note-Taking Techniques
- Organization and Time Management
- Planning Methods and Approaches
- Qualitative Methods, Qualitative Research, Qualitative Analysis
- Reading Notes of Books
- Reading Strategies
- Teaching Public Policy, Public Administration and Public Management
- My Reading Notes of Books on How to Write a Doctoral Dissertation/How to Conduct PhD Research
- Writing a Thesis (Undergraduate or Masters) or a Dissertation (PhD)
- Reading strategies for undergraduates
- Social Media in Academia
- Resources for Job Seekers in the Academic Market
- Writing Groups and Retreats
- Regional Development (Fall 2015)
- State and Local Government (Fall 2015)
- Public Policy Analysis (Fall 2016)
- Regional Development (Fall 2016)
- Public Policy Analysis (Fall 2018)
- Public Policy Analysis (Fall 2019)
- Public Policy Analysis (Spring 2016)
- POLI 351 Environmental Policy and Politics (Summer Session 2011)
- POLI 352 Comparative Politics of Public Policy (Term 2)
- POLI 375A Global Environmental Politics (Term 2)
- POLI 350A Public Policy (Term 2)
- POLI 351 Environmental Policy and Politics (Term 1)
- POLI 332 Latin American Environmental Politics (Term 2, Spring 2012)
- POLI 350A Public Policy (Term 1, Sep-Dec 2011)
- POLI 375A Global Environmental Politics (Term 1, Sep-Dec 2011)
Writing theoretical frameworks, analytical frameworks and conceptual frameworks
Three of the most challenging concepts for me to explain are the interrelated ideas of a theoretical framework, a conceptual framework, and an analytical framework. All three of these tend to be used interchangeably. While I find these concepts somewhat fuzzy and I struggle sometimes to explain the differences between them and clarify their usage for my students (and clearly I am not alone in this challenge), this blog post is an attempt to help discern these analytical categories more clearly.
A lot of people (my own students included) have asked me if the theoretical framework is their literature review. That’s actually not the case. A theoretical framework , the way I define it, is comprised of the different theories and theoretical constructs that help explain a phenomenon. A theoretical framework sets out the various expectations that a theory posits and how they would apply to a specific case under analysis, and how one would use theory to explain a particular phenomenon. I like how theoretical frameworks are defined in this blog post . Dr. Cyrus Samii offers an explanation of what a good theoretical framework does for students .
For example, you can use framing theory to help you explain how different actors perceive the world. Your theoretical framework may be based on theories of framing, but it can also include others. For example, in this paper, Zeitoun and Allan explain their theoretical framework, aptly named hydro-hegemony . In doing so, Zeitoun and Allan explain the role of each theoretical construct (Power, Hydro-Hegemony, Political Economy) and how they apply to transboundary water conflict. Another good example of a theoretical framework is that posited by Dr. Michael J. Bloomfield in his book Dirty Gold, as I mention in this tweet:
In Chapter 2, @mj_bloomfield nicely sets his theoretical framework borrowing from sociology, IR, and business-strategy scholarship pic.twitter.com/jTGF4PPymn — Dr Raul Pacheco-Vega (@raulpacheco) December 24, 2017
An analytical framework is, the way I see it, a model that helps explain how a certain type of analysis will be conducted. For example, in this paper, Franks and Cleaver develop an analytical framework that includes scholarship on poverty measurement to help us understand how water governance and poverty are interrelated . Other authors describe an analytical framework as a “conceptual framework that helps analyse particular phenomena”, as posited here , ungated version can be read here .
I think it’s easy to conflate analytical frameworks with theoretical and conceptual ones because of the way in which concepts, theories and ideas are harnessed to explain a phenomenon. But I believe the most important element of an analytical framework is instrumental : their purpose is to help undertake analyses. You use elements of an analytical framework to deconstruct a specific concept/set of concepts/phenomenon. For example, in this paper , Bodde et al develop an analytical framework to characterise sources of uncertainties in strategic environmental assessments.
A robust conceptual framework describes the different concepts one would need to know to understand a particular phenomenon, without pretending to create causal links across variables and outcomes. In my view, theoretical frameworks set expectations, because theories are constructs that help explain relationships between variables and specific outcomes and responses. Conceptual frameworks, the way I see them, are like lenses through which you can see a particular phenomenon.
A conceptual framework should serve to help illuminate and clarify fuzzy ideas, and fill lacunae. Viewed this way, a conceptual framework offers insight that would not be otherwise be gained without a more profound understanding of the concepts explained in the framework. For example, in this article, Beck offers social movement theory as a conceptual framework that can help understand terrorism . As I explained in my metaphor above, social movement theory is the lens through which you see terrorism, and you get a clearer understanding of how it operates precisely because you used this particular theory.
Dan Kaminsky offered a really interesting explanation connecting these topics to time, read his tweet below.
I think this maps to time. Theoretical frameworks talk about how we got here. Conceptual frameworks discuss what we have. Analytical frameworks discuss where we can go with this. See also legislative/executive/judicial. — Dan Kaminsky (@dakami) September 28, 2018
One of my CIDE students, Andres Ruiz, reminded me of this article on conceptual frameworks in the International Journal of Qualitative Methods. I’ll also be adding resources as I get them via Twitter or email. Hopefully this blog post will help clarify this idea!
You can share this blog post on the following social networks by clicking on their icon.
Posted in academia .
Tagged with analytical framework , conceptual framework , theoretical framework .
By Raul Pacheco-Vega – September 28, 2018
7 Responses
Stay in touch with the conversation, subscribe to the RSS feed for comments on this post .
Thanks, this had some useful clarifications for me!
I GOT CONFUSED AGAIN!
No need to be confused!
Thanks for the Clarification, Dr Raul. My cluttered mind is largely cleared, now.
Thanks,very helpful
I too was/am confused but this helps 🙂
Thank you very much, Dr.
Leave a Reply Cancel Some HTML is OK
Name (required)
Email (required, but never shared)
or, reply to this post via trackback .
About Raul Pacheco-Vega, PhD
Find me online.
My Research Output
- Google Scholar Profile
- Academia.Edu
- ResearchGate
My Social Networks
- Polycentricity Network
Recent Posts
- The value and importance of the pre-writing stage of writing
- My experience teaching residential academic writing workshops
- “State-Sponsored Activism: Bureaucrats and Social Movements in Brazil” – Jessica Rich – my reading notes
- Reading Like a Writer – Francine Prose – my reading notes
- Using the Pacheco-Vega workflows and frameworks to write and/or revise a scholarly book
Recent Comments
- Charlotte on The value and importance of the pre-writing stage of writing
- Raul Pacheco-Vega on The value and importance of the pre-writing stage of writing
- Noni on Developing a structured daily routine for writing and research
- Alan Parker on Project management for academics I: Managing a research pipeline
Follow me on Twitter:
Proudly powered by WordPress and Carrington .
Carrington Theme by Crowd Favorite
Lean Six Sigma Training Certification
- Facebook Instagram Twitter LinkedIn YouTube
- (877) 497-4462
Analytical Modeling: A Guide to Data-Driven Decision Making
July 30th, 2024
Analytical modeling is a comprehensive approach that employs mathematical models, statistical algorithms, and data analysis methods to understand, interpret, and predict outcomes based on historical data and known variables.
At its core, it represents a quantitative and computational framework for dissecting intricate systems, identifying patterns, and informing strategic decision-making processes.
Key Highlights
- Understanding Analytical modeling
- Learn key concepts and techniques
- Benefits of Analytical modeling
- Case studies span various domains
- Best practices
- Emerging trends for further revolutionize the field of analytical modeling.
Introduction to Analytical Modeling
Analytical modeling, or analytics modeling, is a comprehensive approach that employs mathematical models, statistical algorithms, and data analysis techniques to gain insights, make predictions, and inform business strategies.
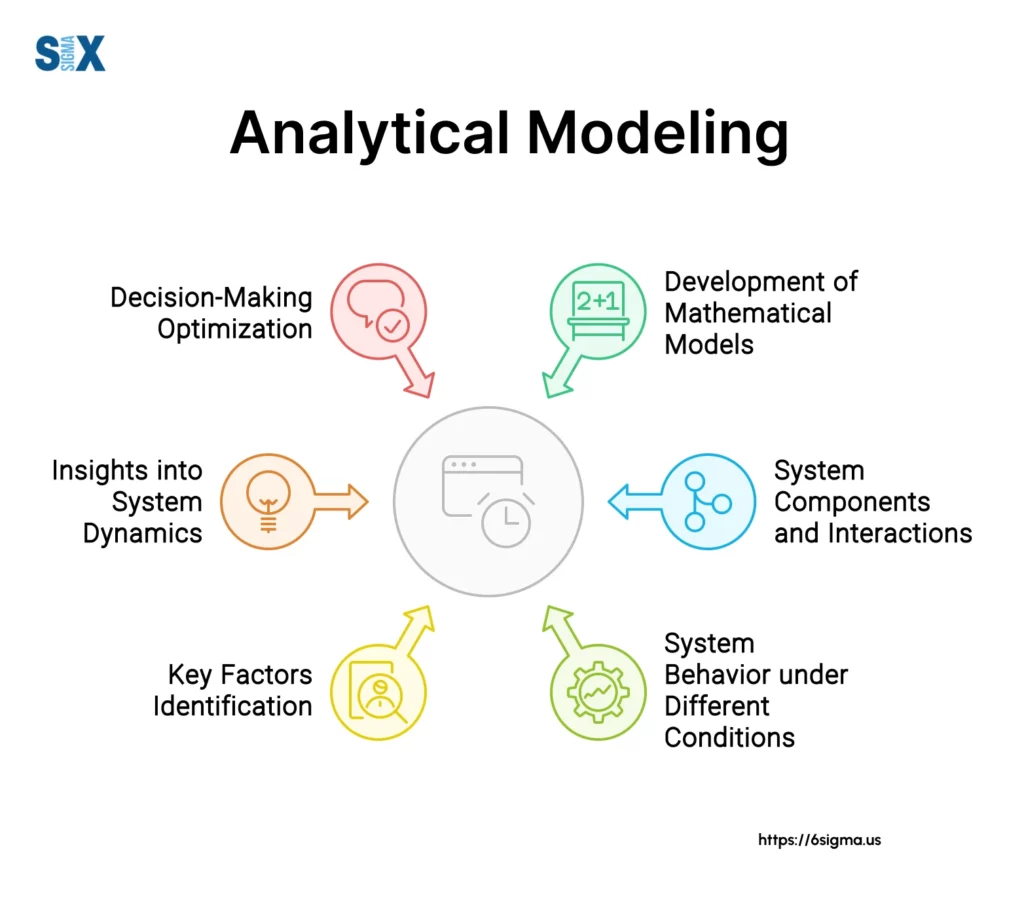
It is a quantitative and computational framework that allows organizations to dissect intricate systems, identify patterns, and understand the relationships between various variables and factors influencing specific outcomes.
Importance in data-driven decision making
Analytical modeling has emerged as an indispensable tool for organizations seeking to gain a competitive edge.
By leveraging advanced analytical techniques, businesses can unlock insights hidden within complex data sets, accurately define problems, formulate solutions, and anticipate outcomes based on empirical evidence rather than intuition or guesswork.
It promotes data-driven decision-making, enabling leaders to base their strategies and actions on quantitative analysis rather than relying solely on subjective theories or personal experiences.
This data-driven approach has proven invaluable in driving continuous improvement, optimizing processes, and achieving better outcomes across various industries.
Applications of Analytical Modeling across industries
The applications of analytical modeling span a wide array of industries and domains, including but not limited to:
- Business intelligence : Analytical modeling plays a crucial role in business intelligence, enabling organizations to extract valuable insights from data and make informed decisions related to operations, marketing, finance, and strategic planning.
- Operations research : This field heavily relies on analytical modeling techniques to optimize processes, allocate resources efficiently, and streamline supply chain operations.
- Finance : Financial institutions leverage it for risk assessment, portfolio management, credit scoring, and fraud detection.
- Marketing : Marketing professionals use it for customer segmentation, targeted advertising, and predicting consumer behavior.
- Healthcare : In the healthcare industry, it is employed for disease prediction, patient risk stratification, and optimizing resource allocation in healthcare facilities.
- Manufacturing : Analytical modeling techniques are instrumental in manufacturing settings’ quality control, process optimization, and predictive maintenance.
These are just a few examples of the vast applications of analytical modeling, which continue to expand as organizations increasingly recognize the value of data-driven decision-making.
Key Concepts and Techniques of Analytical Modeling
Take a look at the key concepts and techniques in analytical modeling.
Mathematical Models
Regression analysis
Regression analysis is a fundamental technique that aims to establish relationships between dependent and independent variables.
By analyzing historical data, regression models can identify patterns and quantify the impact of various factors on a particular outcome.
Common applications of regression analysis include demand forecasting, pricing optimization, and credit risk assessment.
Optimization techniques
Optimization techniques are employed in analytical modeling to find the best possible solution or combination of variables that maximize or minimize a specific objective function, subject to certain constraints.
These techniques are widely used in resource allocation, scheduling, portfolio optimization, and supply chain management.
Linear programming, integer programming, and nonlinear programming are examples of optimization techniques that can be applied to different problem domains.
Simulation modeling
Simulation modeling involves creating a virtual representation of a system or process to study its behavior under various conditions.
By incorporating relevant variables and constraints, organizations can experiment with different scenarios and assess the potential impact of decisions before implementing them in the real world.
This approach is particularly valuable in complex environments where analytical solutions are challenging to derive.
Monte Carlo simulation and discrete-event simulation are two commonly used simulation modeling techniques in fields such as risk analysis, process improvement, and logistics management.
Statistical Algorithms
Machine learning
Machine learning algorithms are a powerful component, enabling systems to learn from data and make predictions or decisions without being explicitly programmed.
These algorithms can identify patterns, classify data, and adapt to changing conditions, making them invaluable in areas such as predictive maintenance, fraud detection, and recommendation systems.
Supervised learning, unsupervised learning, and reinforcement learning are the three main types of machine learning algorithms used in analytical modeling.
Predictive analytics
Predictive analytics is a branch of analytical modeling that focuses on forecasting future outcomes or behaviors based on historical data and known variables.
Forecasting models
Forecasting models are a crucial component of analytical modeling, aimed at predicting future trends or events based on past data and identified patterns.
Time series analysis, exponential smoothing, and autoregressive integrated moving average (ARIMA) models are commonly used for forecasting applications in areas such as sales planning, inventory management, and resource allocation.
Data Analysis with Analytical Modeling
Descriptive analytics
Descriptive analytics is the foundation of analytical modeling, involving the summarization and visualization of historical data.
This type of analysis answers the question “ What happened? ” by presenting key performance indicators (KPIs), dashboards, and reports that provide insights into past events and current states.
Diagnostic analytics
Building upon descriptive analytics, diagnostic analytics aims to uncover the underlying causes or drivers behind observed outcomes.
Prescriptive analytics
Prescriptive analytics represents the most advanced form of analytical modeling, combining insights from descriptive, diagnostic, and predictive analyses to recommend the best course of action for a given scenario.
Benefits of Analytical Modeling
Informed decision making
One of the primary benefits of analytical modeling is its ability to support informed decision-making.
By leveraging data-driven insights and quantitative analysis, organizations can accurately define problems, formulate solutions, and anticipate outcomes rather than relying solely on intuition or subjective theories.
Logical information structuring
Analytical modeling facilitates the logical structuring and organization of information.
By establishing mathematical relationships between variables and factors, analytical models enable businesses to trace general outcomes back to specific sources or root causes.
The collaborative and iterative approach
The objective nature of analytical modeling makes it an ideal tool for establishing a common foundation for discussion and collaboration within organizations.
Rather than attempting to reconcile subjective theories, analytical data provides a universal reference framework that can be iteratively refined and improved as new information becomes available.
Process optimization
Analytical modeling techniques, such as optimization modeling and simulation, can be leveraged to identify opportunities for process optimization.
By analyzing various scenarios and constraints, organizations can determine the most efficient allocation of resources, streamline workflows, and minimize waste or inefficiencies, ultimately leading to improved productivity and cost savings.
Risk assessment
Risk assessment is a critical application of analytical modeling, particularly in industries such as finance, healthcare, and manufacturing.
By analyzing historical data and incorporating relevant variables, analytical models can quantify and predict potential risks, enabling organizations to develop mitigation strategies and make informed decisions regarding risk management.
Customer segmentation
In marketing and customer relationship management, analytical modeling plays a vital role in customer segmentation.
By analyzing customer data, behavioral patterns, and demographic information, organizations can identify distinct customer segments and tailor their products, services, and marketing strategies to better meet the needs and preferences of each segment, leading to increased customer satisfaction and loyalty.
Case Studies
Business analytics.
Marketing Analytics
Marketing analytics leverages these techniques to gain insights into customer behavior, optimize marketing campaigns, and drive revenue growth.
By analyzing customer data, market trends, and campaign performance, organizations can develop targeted marketing strategies, predict customer churn, and optimize resource allocation for maximum impact.
Financial modeling
Financial institutions heavily rely on analytical modeling for various applications, including risk management, portfolio optimization, credit scoring, and fraud detection.
Quantitative models are employed to assess credit risk, optimize investment portfolios, detect fraudulent activities, and ensure compliance with regulatory requirements.
Supply chain analytics
In the realm of supply chain management, it plays a crucial role in optimizing operations, reducing costs, and improving efficiency.
By analyzing data related to inventory levels, demand patterns, transportation networks, and supplier performance, organizations can optimize inventory management, route planning, and supplier selection processes.
Industry-specific Examples
Healthcare analytics
The healthcare industry is leveraging analytical modeling to improve patient outcomes, optimize resource allocation, and enhance operational efficiency.
Predictive models are used for disease prediction, risk stratification, and identifying high-risk patients, enabling proactive interventions and personalized care plans.
Retail analytics
In the retail sector, analytical modeling techniques are employed for demand forecasting, inventory management, pricing optimization, and location analysis.
By analyzing sales data, customer behavior, and market trends, retailers can make informed decisions regarding product assortments, pricing strategies, and store locations, ultimately enhancing customer satisfaction and profitability.
IoT analytics
The Internet of Things (IoT) has generated vast amounts of data from connected devices and sensors.
Analytical modeling plays a crucial role in extracting insights from this data, enabling predictive maintenance, asset optimization, and real-time monitoring in various industries, such as manufacturing, energy, and transportation.
Best Practices and Challenges of Analytical Modeling
The accuracy and reliability of analytical models are highly dependent on the quality of the input data.
Garbage in, garbage out – poor data input will inevitably lead to subpar outputs and erroneous insights.
Therefore, ensuring the quality, completeness, and relevance of data is a critical prerequisite for successful analytical modeling.
Data cleaning and preparation
Data cleaning and preparation are essential steps in the analytical modeling process.
This involves identifying and addressing issues such as missing values, inconsistencies, outliers, and formatting errors.
Techniques like data imputation, normalization, and feature engineering may be employed to transform raw data into a suitable format for modeling.
Model Selection and Validation
Choosing appropriate models
Selecting the most appropriate analytical model is crucial for obtaining accurate and actionable insights.
Different models are designed for specific types of problems or data structures, and using an inappropriate model can lead to inaccurate results or suboptimal solutions.
Careful consideration of the problem domain, data characteristics, and modeling assumptions is necessary when choosing the most suitable analytical technique.
Cross-validation techniques
Cross-validation techniques, such as k-fold cross-validation and holdout validation, are essential for evaluating the performance and generalization capability of analytical models.
These techniques involve partitioning the available data into training and testing sets, enabling the assessment of model accuracy and preventing overfitting or underfitting issues.
Interpretation and Communication with Analytical Modeling
Data visualization
Effective data visualization is a critical component of analytical modeling, as it facilitates the interpretation and communication of complex insights.
By presenting data and model outputs in a clear and visually appealing manner, stakeholders can more easily understand patterns, trends, and relationships, enabling informed decision-making.
Communicating insights effectively
While analytical models can generate valuable insights, it is equally important to communicate these insights effectively to various stakeholders, including executives, managers, and domain experts.
Clear and concise communication, tailored to the audience’s level of technical expertise, is essential for ensuring that the insights derived from analytical modeling are understood and can be translated into actionable strategies.
Ethical Considerations
Bias and fairness in modeling
Analytical models can be influenced by biases present in the underlying data or introduced during the modeling process itself.
It is crucial to address potential sources of bias, such as sample selection bias, algorithmic bias, or human bias, to ensure fair and equitable outcomes.
Techniques like bias testing, model auditing, and ethical AI frameworks can help mitigate these risks.
Privacy and data security
As analytical modeling often involves sensitive and personal data, maintaining privacy and data security is of utmost importance.
Organizations must comply with relevant data protection regulations and implement robust security measures to safeguard sensitive information from unauthorized access, breaches, or misuse.
Techniques such as data anonymization , encryption, and access controls can help mitigate privacy and security risks.
Future Trends and Emerging Technologies
With the exponential growth of data generated from various sources, such as social media, sensors, and online platforms, big data modeling has emerged as a critical area of analytical modeling.
This field focuses on developing techniques and technologies to handle and extract insights from massive, complex, and diverse data sets.
Distributed computing frameworks, NoSQL databases, and advanced machine learning algorithms are enabling organizations to leverage big data for competitive advantage.
By using advanced mathematical models, statistical algorithms, and data analysis techniques , businesses can accurately define problems, formulate solutions, and anticipate outcomes based on empirical evidence.
While the potential benefits are substantial, ensuring data quality, selecting appropriate models, validating results, communicating insights effectively, and addressing ethical considerations like bias and data privacy are crucial best practices.
By using analytical modeling as an integral part of their decision-making processes and staying up to date on the latest developments, organizations can unlock a competitive advantage and drive sustainable growth.
SixSigma.us offers both Live Virtual classes as well as Online Self-Paced training. Most option includes access to the same great Master Black Belt instructors that teach our World Class in-person sessions. Sign-up today!
Virtual Classroom Training Programs Self-Paced Online Training Programs
SixSigma.us Accreditation & Affiliations

Monthly Management Tips
- Be the first one to receive the latest updates and information from 6Sigma
- Get curated resources from industry-experts
- Gain an edge with complete guides and other exclusive materials
- Become a part of one of the largest Six Sigma community
- Unlock your path to become a Six Sigma professional
" * " indicates required fields
Marketing Research
21 analytical models.
Marketing models consists of
- Analytical Model: pure mathematical-based research
- Empirical Model: data analysis.
“A model is a representation of the most important elements of a perceived real-world system”.
Marketing model improves decision-making
Econometric models
- Description
Optimization models
- maximize profit using market response model, cost functions, or any constraints.
Quasi- and Field experimental analyses
Conjoint Choice Experiments.
“A decision calculus will be defined as a model-based set of procedures for processing data and judgments to assist a manager in his decision making” ( Little 1976 ) :
- easy to control
- as complete as possible
- easy to communicate with
| Type of game | |||
|---|---|---|---|
| Static | Dynamic | ||
| Info Content | Complete | Nash | Subgame perfect |
| Incomplete | Bayesian Nash (Auctions) | Perfect Bayesian (signaling) |
( K. S. Moorthy 1993 )
Mathematical Theoretical Models
Logical Experimentation
An environment as a model, specified by assumptions
Math assumptions for tractability
Substantive assumptions for empirical testing
Decision support modeling describe how things work, and theoretical modeling present how things should work.
Compensation package including salaries and commission is a tradeoff between reduced income risk and motivation to work hard.
Internal and External Validity are questions related to the boundaries conditions of your experiments.
“Theories are tested by their predictions, not by the realism of their super model assumptions.” (Friedman, 1953)
( McAfee and McMillan 1996 )
Competition is performed under uncertainty
Competition reveals hidden information
Independent-private-values case: selling price = second highest valuation
It’s always better for sellers to reveal information since it reduces chances of cautious bidding that is resulted from the winner’s curse
Competition is better than bargaining
- Competition requires less computation and commitment abilities
Competition creates effort incentives
( Leeflang et al. 2000 )
Types of model:
Predictive model
Sales model: using time series data
Trial rate: using exponential growth.
Product growth model: Bass ( 1969 )
Descriptive model
Purchase incidence and purchase timing : use Poisson process
Brand choice: Markov models or learning models.
Pricing decisions in an oligopolistic market Howard and Morgenroth ( 1968 )
Normative model
- Profit maximization based on price, adverting and quality ( Dorfman and Steiner 1976 ) , extended by ( H. V. Roberts, Ferber, and Verdoorn 1964 ; Lambin 1970 )
Later, Little ( 1970 ) introduced decision calculus and then multinomial logit model ( Peter M. Guadagni and Little 1983 )
Potential marketing decision automation:
Promotion or pricing programs
Media allocation
Distribution
Product assortment
Direct mail solicitation
( K. S. Moorthy 1985 )
Definitions:
Rationality = maximizing subjective expected utility
Intelligence = recognizing other firms are rational.
Rules of the game include
feasible set of actions
utilities for each combination of moves
sequence of moves
the structure of info (who knows what and when?)
Incomplete info stems from
unknown motivations
unknown ability (capabilities)
different knowledge of the world.
Pure strategy = plan of action
A mixed strategy = probability dist of pure strategies.
Strategic form representation = sets of possible strategies for every firm and its payoffs.
Equilibrium = a list of strategies in which “no firm would like unilaterally to change its strategy.”
Equilibrium is not outcome of a dynamic process.
Equilibrium Application
Oligopolistic Competition
Cournot (1838): quantities supplied: Cournot equilibrium. Changing quantities is more costly than changing prices
Bertrand (1883): Bertrand equilibrium: pricing.
Perfect competition
Product Competition: Hotelling (1929): Principle of Minimum Differentiation is invalid.
first mover advantage
deterrent strategy
optimal for entrants or incumbents
Perfectness of equilibria
Subgame perfectness
Sequential rationality
Trembling-hand perfectness
Application
Product and price competition in Oligopolies
Strategic Entry Deterrence
Dynamic games
Long-term competition in oligopolies
Implicit Collusion in practice : price match from leader firms
Incomplete Information
Durable goods pricing by a monopolist
predatory pricing and limit pricing
reputation, product quality, and prices
Competitive bidding and auctions
21.1 Building An Analytical Model
Notes by professor Sajeesh Sajeesh
Step 1: Get “good” idea (either from literature or industry)
Step 2: Assess the feasibility of the idea
Is it interesting?
Can you tell a story?
Who is the target audience?
Opportunity cost
Step 3: Don’t look at the literature too soon
- Even when you have an identical model as in the literature, it’s ok (it allows you to think)
Step 4: BUild the model
Simplest model first: 1 period, 2 product , linear utility function for consumers
Write down the model formulation
Everything should be as simple as possible .. but no simpler
Step 5: Generalizing the model
- Adding complexity
Step 6: Searching the literature
- If you find a paper, you can ask yourself why you didn’t do what the author has done.
Step 7: Give a talk /seminar
Step 8: Write the paper
21.2 Hotelling Model
( KIM and SERFES 2006 ) : A location model with preference variety
( Hotelling 1929 )
Stability in competition
Duopoly is inherently unstable
Bertrand disagrees with Cournot, and Edgeworth elaborates on it.
- because Cournot’s assumption of absolutely identical products between firms.
seller try to \(p_2 < p_1 c(l-a-b)\)
the point of indifference
\[ p_1 + cx = p_2 + cy \]
c = cost per unit of time in each unit of line length
q = quantity
x, y = length from A and B respectively
\[ a + x + y + b = l \]
is the length of the street
Hence, we have
\[ x = 0.5(l - a - b + \frac{p_2- p_1}{c}) \\ y = 0.5(l - a - b + \frac{p_1- p_2}{c}) \]
Profits will be
\[ \pi_1 = p_1 q_1 = p_1 (a+ x) = 0.5 (l + a - b) p_1 - \frac{p_1^2}{2c} + \frac{p_1 p_2}{2c} \\ \pi_2 = p_2 q_2 = p_2 (b+ y) = 0.5 (l + a - b) p_2 - \frac{p_2^2}{2c} + \frac{p_1 p_2}{2c} \]
To set the price to maximize profit, we have
\[ \frac{\partial \pi_1}{\partial p_1} = 0.5 (l + a - b) - \frac{p_1}{c} + \frac{p_2}{2c} = 0 \\ \frac{\partial \pi_2}{\partial p_2} = 0.5 (l - a + b) - \frac{p_2}{c} + \frac{p_1}{2c} = 0 \]
which equals
\[ p_1 = c(l + \frac{a-b}{3}) \\ p_2 = c(l - \frac{a-b}{3}) \]
\[ q_1 = a + x = 0.5 (l + \frac{a -b}{3}) \\ q_2 = b + y = 0.5 (l - \frac{a-b}{3}) \]
with the SOC satisfied
In case of deciding locations, socialism works better than capitalism
( d’Aspremont, Gabszewicz, and Thisse 1979 )
- Principle of Minimum Differentiation is invalid
\[ \pi_1 (p_1, p_2) = \begin{cases} ap_1 + 0.5(l-a-b) p_1 + \frac{1}{2c}p_1 p_2 - \frac{1}{2c}p_1^2 & \text{if } |p_1 - p_2| \le c(l-a-b) \\ lp_1 & \text{if } p_1 < p_2 - c(l-a-b) \\ 0 & \text{if } p_1 > p_2 + c(l-a-b) \end{cases} \]
\[ \pi_2 (p_1, p_2) = \begin{cases} bp_2 + 0.5(l-a-b) p_2 + \frac{1}{2c}p_1 p_2 - \frac{1}{2c}p_2^2& \text{if } |p_1 - p_2| \le c(l-a-b) \\ lp_2 & \text{if } p_2 < p_1 - c(l-a-b) \\ 0 & \text{if } p_2 > p_1 + c(l-a-b) \end{cases} \]
21.3 Positioning Models
Tabuchi and Thisse ( 1995 )
Relax Hotelling’s model’s assumption of uniform distribution of consumers to non-uniform distribution.
Assumptions:
Consumers distributed over [0,1]
\(F(x)\) = cumulative distribution of consumers where \(F(1) = 1\) = total population
2 distributions:
Traditional uniform density: \(f(x) =1\)
New: triangular density: \(f(x) = 2 - 2|2x-1|\) which represents consumer concentration
Transportation cost = quadratic function of distance.
Hence, marginal consumer is
\[ \bar{x} = (p_2 - p_1 + x^2_2-x_1^2)/2(x_2-x_1) \]
then when \(x_1 < x_2\) the profit function is
\[ \Pi_1 = p_1 F(\bar{x}) \]
\[ \Pi_2 = p_2[1-F(\bar{x})] \]
and vice versa for \(x_1 >x_2\) , and Bertrand game when \(x_1 = x_2\)
If firms pick simultaneously their locations, and then simultaneously their prices, and consumer density function is log-concave, then there is a unique Nash price equilibrium
Under uniform distribution, firms choose to locate as far apart as possible (could be true when observing shopping centers are far away from cities), but then consumers have to buy products that are far away from their ideal.
Under triangular density, no symmetric location can be found, but two asymmetric Nash location equilibrium can still be possible (decrease in equilibrium profits of both firms)
If firms pick sequentially their locations, and pick their prices simultaneously,
- Under both uniform and triangular, first entrant will locate at the market center
Sajeesh and Raju ( 2010 )
Model satiation (variety-seeking) as a relative reduction in the willingness to pay of the previously purchased brand. also known as negative state dependence
Previous studies argue that in the presence of variety seeking consumers, firms should enjoy higher prices and profits, but this paper argues that average prices and profits are lower.
- Firms should charge lower prices in the second period to prevent consumers from switching.
Period 0, choose location simultaneously
Period 1, choose prices simultaneously
Period 2, firms choose prices simultaneously
- K. S. Moorthy ( 1988 )
- 2 (identical) firms pick product (quality) first, then price.
Tyagi ( 2000 )
Extending Hotelling ( 1929 ) Tyagi ( 1999b ) Tabuchi and Thisse ( 1995 )
Two firms enter sequentially , and have different cost structures .
Paper shows second mover advantage
KIM and SERFES ( 2006 )
Consumers can make multiple purchases.
Some consumers are loyal to one brand, and others consume more than one product.
Shreay, Chouinard, and McCluskey ( 2015 )
- Quantity surcharges from different sizes of the same product (i.e., imperfect substitute or differentiated products) can be led by consumer preferences.
21.4 Market Structure and Framework
Basic model utilizing aggregate demand
Bertrand Equilibrium: Firms compete on price
Cournot Market structure: Firm compete on quantity
Stackelberg Market structure: Leader-Follower model
Because we start with the quantity demand function, it is important to know where it’s derived from Richard and Martin ( 1980 )
- studied how two firms compete on product quality and price (both simultaneous and sequential)
21.4.1 Cournot - Simultaneous Games
\[ TC_i = c_i q_i \text{ where } i= 1,2 \\ P(Q) = a - bQ \\ Q = q_1 +q_2 \\ \pi_1 = \text{price} \times \text{quantity} - \text{cost} = [a - b(q_1 +q_2)]q_1 - c_1 q_1 \\ \pi_2 = \text{price} \times \text{quantity} - \text{cost} = [a - b(q_1 +q_2)]q_1 - c_2 q_2 \\ \]
From (21.1)
is called reaction function, for best response function
From (21.2)
\[ q_1 = \frac{a-c_1}{2b} - \frac{a-c_2}{4b} + \frac{q_1}{4} \]
\[ q_1^* = \frac{a-2c_1+ c_2}{3b} \\ q_2^* = \frac{a-2c_2 + c_1}{3b} \]
Total quantity is
\[ Q = q_1 + q_2 = \frac{2a-c_1 -c_2}{3b} \]
\[ a-bQ = \frac{a+c_1+c_2}{3b} \]
21.4.2 Stackelberg - Sequential games
also known as leader-follower games
Stage 1: Firm 1 chooses quantity
Stage 2: Firm 2 chooses quantity
\[ c_2 = c_1 = c \]
Stage 2: reaction function of firm 2 given quantity firm 1
\[ R_2(q_1) = \frac{a-c}{2b} - \frac{q_1}{2} \]
\[ \pi_1 = [a-b(q_1 + \frac{a-c}{2b} - \frac{q_1}{2})]q_1 - cq_1 \\ = [a-b( \frac{a-c}{2b} + \frac{q_1}{2}]q_1 + cq_1 \]
\[ \frac{d \pi_1}{d q_1} = 0 \]
\[ \frac{a+c}{2} - b q_1 -c =0 \]
The Stackelberg equilibrium is
\[ q_1^* = \frac{a-c}{2b} \\ q_2^* = \frac{a-c}{4b} \]
Under same price (c), Cournot =
\[ q_1 = q_2 = \frac{a-c}{3b} \]
Leader produces more whereas the follower produces less compared to Cournot
\[ \frac{d \pi_W^*}{d \beta} <0 \]
for the entire quantity range \(d < \bar{d}\)
As \(\beta\) increases in \(\pi_W^*\) Firm W wants to reduce \(\beta\) .
Low \(\beta\) wants more independent
Firms W want more differentiated product
On the other hand,
\[ \frac{d \pi_S^*}{d \beta} <0 \]
for a range of \(d < \bar{d}\)
Firm S profit increases as \(\beta\) decreases when d is small
Firm S profit increases as \(\beta\) increases when d is large
Firm S profit increases as as product are more substitute when d is large
Firm S profit increases as products are less differentiated when d is large
21.5 More Market Structure
Dixit ( 1980 )
Based on Bain-Sylos postulate: incumbents can build capacity such that entry is unprofitability
Investment in capacity is not a credibility threat if incumbents can change their capacity.
Incumbent cannot deter entry
Tyagi ( 1999a )
More retailers means greater competition, which leads to lower prices for customers.
Effect of \((n+1)\) st retailer entry
Competition effect (lower prices)
Effect on price (i.e., wholesale price), also known as input cost effect
Manufacturers want to increase wholesale price because now manufacturers have higher bargaining power, which leads other retailers to reduce quantity (bc their choice of quantity is dependent on wholesale price), and increase in prices.
Jerath, Sajeesh, and Zhang ( 2016 )
Organized Retailer enters a market
Inefficient unorganized retailers exit
Remaining unorganized retailers increase their prices. Thus, customers will be worse off.
Amaldoss and Jain ( 2005 )
consider desire for uniqueness and conformism on pricing conspicuous goods
Two routes:
higher desire for uniqueness leads to higher prices and profits
higher desire for conformity leads to lower prices and profits
Under the analytical model and lab text, consumers’ desire for unique is increased from price increases, not the other way around.
\[ U_A = V - p_A - \theta t_s - \lambda_s(n_A) \\ U_B = V - p_B - (1-\theta) t_s - \lambda_s(n_B) \]
\(\lambda_s\) = sensitivity towards externality.
\(\theta\) is the position in the Hotelling’s framework.
\(t_s\) is transportation cost.
\[ U_A = V - p_A - \theta t_s + \lambda_c(n_A) \\ U_B = V - p_B - (1-\theta) t_s + \lambda_c(n_B) \]
Rational Expectations Equilibrium
If your expectations are rational, then your expectation will be realized in equilibrium
Say, Marginal Snob = \(\theta_s\) and \(\beta\) = number of snob in the market
\[ U_A^c \equiv U_B^c = \theta_s \]
Conformists
\[ U_A^c =U_B^c = \theta_c \]
Then, according to rational expectations equilibrium, we have
\[ \beta \theta_s +( 1- \beta) \theta_c = n_A \\ \beta (1-\theta_s) +( 1- \beta) (1-\theta_c) = n_B \]
\(\beta \theta_s\) = Number of snobs who buy from firm A
\((1-\beta)\theta_c\) = Number of conformists who buy from firm B
\(\beta(1-\theta_s)\) = Number of snobs who buy from firm B
\((1-\beta)(1-\theta_c)\) = Number of conformists who buy from firm B
which is the rational expectations equilibrium (whatever we expect happens in reality).
In other words, expectation are realized in equilibrium.
The number of people expected to buy the product is endogenous in the model, which will be the actual number of people who will buy it in the market.
We should not think of the expected value here in the same sense as expected value in empirical research ( \(E(.)\) ) because the expected value here is without any errors (specifically, measurement error).
- The utility function for snobs is such that overall when price increase for one product, snob will like to buy the product more. When price increases, conformist will reduce the purchase.
Balachander and Stock ( 2009 )
Adding a Limited edition product has a positive effect on profits (via increased willingness of consumers to pay for such a product), but negative strategic effect (via increasing price competition between brands)
Under quality differentiation, high-quality brand gain from LE products
Under horizontal taste differentiation, negative strategic effects lead to lower equilibrium profits for both brands, but they still have to introduce LE products because of prisoners’ dilemma
Sajeesh, Hada, and Raju ( 2020 )
two consumer segments:
functionality-oriented
exclusivity-oriented
Firm increase value enhancements when functionality-oriented consumers perceive greater product differentiation
Firms decrease value enhancements if exclusivity-oriented perceive greater product differentiation
21.6 Market Response Model
Marketing Inputs:
- Selling effort
- advertising spending
- promotional spending
Marketing Outputs:
")
Give phenomena for a good model:
- P1: Dynamic sales response involves a sales growth rate and a sales decay rate that are different
- P2: Steady-state response can be concave or S-shaped . Positive sales at 0 adverting.
- P3: Competitive effects
- P4: Advertising effectiveness dynamics due to changes in media, copy, and other factors.
- P5: Sales still increase or fall off even as advertising is held constant.
Saunder (1987) phenomena
- P1: Output = 0 when Input = 0
- P2: The relationship between input and output is linear
- P3: Returns decrease as the scale of input increases (i.e., additional unit of input gives less output)
- P4: Output cannot exceed some level (i.e., saturation)
- P5: Returns increase as scale of input increases (i.e., additional unit of input gives more output)
- P6: Returns first increase and then decrease as input increases (i.e., S-shaped return)
- P7: Input must exceed some level before it produces any output (i.e., threshold)
- P8: Beyond some level of input, output declines (i.e., supersaturation point)
")
Aggregate Response Models
Linear model: \(Y = a + bX\)
Through origin
can only handle constant returns to scale (i.e., can’t handle concave, convex, and S-shape)
The Power Series/Polynomial model: \(Y = a + bX + c X^2 + dX^3 + ...\)
- can’t handle saturation and threshold
Fraction root model/ Power model: \(Y = a+bX^c\) where c is prespecified
c = 1/2, called square root model
c = -1, called reciprocal model
c can be interpreted as elasticity if a = 0.
c = 1, linear
c <1, decreasing return
c>1, increasing returns
Semilog model: \(Y = a + b \ln X\)
- Good when constant percentage increase in marketing effort (X) result in constant absolute increase in sales (Y)
Exponential model: \(Y = ae^{bX}\) where X >0
b > 0, increasing returns and convex
b < 0, decreasing returns and saturation
Modified exponential model: \(Y = a(1-e^{-bX}) +c\)
Decreasing returns and saturation
upper bound = a + c
lower bound = c
typically used in selling effort
Logistic model: \(Y = \frac{a}{a+ e^{-(b+cX)}}+d\)
increasing return followed by decreasing return to scale, S-shape
saturation = a + d
good with saturation and s-shape
Gompertz model
ADBUDG model ( Little 1970 ) : \(Y = b + (a-b)\frac{X^c}{d + X^c}\)
c > 1, S-shaped
0 < c < 1
saturation effect
upper bound at a
lower bound at b
typically used in advertising and selling effort.
can handle, through origin, concave, saturation, S-shape
Additive model for handling multiple Instruments: \(Y = af(X_1) + bg(X_2)\)
Multiplicative model for handling multiple instruments: \(Y = aX_1^b X_2^c\) where c and c are elasticities. More generally, \(Y = af(X_1)\times bg(X_2)\)
Multiplicative and additive model: \(Y = af(X_1) + bg(X_2) + cf(X_1) g(X_2)\)
Dynamic response model: \(Y_t = a_0 + a_1 X_t + \lambda Y_{t-1}\) where \(a_1\) = current effect, \(\lambda\) = carry-over effect
Dynamic Effects
Carry-over effect: current marketing expenditure influences future sales
- Advertising adstock/ advertising carry-over is the same thing: lagged effect of advertising on sales
Delayed-response effect: delays between when marketing investments and their impact
Customer holdout effects
Hysteresis effect
New trier and wear-out effect
Stocking effect
Simple Decay-effect model:
\[ A_t = T_t + \lambda T_{t-1}, t = 1,..., \]
- \(A_t\) = Adstock at time t
- \(T_t\) = value of advertising spending at time t
- \(\lambda\) = decay/ lag weight parameter
Response Models can be characterized by:
The number of marketing variables
whether they include competition or not
the nature of the relationship between the input variables
- Linear vs. S-shape
whether the situation is static vs. dynamic
whether the models reflect individual or aggregate response
the level of demand analyzed
- sales vs. market share
Market Share Model and Competitive Effects: \(Y = M \times V\) where
Y = Brand sales models
V = product class sales models
M = market-share models
Market share (attraction) models
\[ M_i = \frac{A_i}{A_1 + ..+ A_n} \]
where \(A_i\) attractiveness of brand i
Individual Response Model:
Multinomial logit model representing the probability of individual i choosing brand l is
\[ P_{il} = \frac{e^{A_{il}}}{\sum_j e^{A_{ij}}} \]
- \(A_{ij}\) = attractiveness of product j for individual i \(A_{ij} = \sum_k w_k b_{ijk}\)
- \(b_{ijk}\) = individual i’s evaluation of product j on product attribute k, where the summation is over all the products that individual i is considering to purchase
- \(w_k\) = importance weight associated with attribute k in forming product preferences.
21.7 Technology and Marketing Structure and Economics of Compatibility and Standards
21.8 conjoint analysis and augmented conjoint analysis.
More technical on 27.1
Jedidi and Zhang ( 2002 )
- Augmenting Conjoint Analysis to Estimate Consumer Reservation Price
Using conjoint analysis (coefficients) to derive at consumers’ reservation prices for a product in a category.
Can be applied in the context of
product introduction
calculating customer switching effect
the cannibalization effect
the market expansion effect
\[ Utility(Rating) = \alpha + \beta_i Attribute_i \]
where \(\alpha\)
Netzer and Srinivasan ( 2011 )
Break conjoint analysis down to a sequence of constant-sum paired comparison questions.
Can also calculate the standard errors for each attribute importance.
21.9 Distribution Channels
McGuire and Staelin ( 1983 )
- Two manufacturing (wholesaling) firms differentiated and competing products: Upstream firms (manufacturers) and downstream channel members (retailers)
3 types of structure:
- Both manufacturers with privately owned retailers (4 players: 2 manufacturers, 2 retailers)
- Both vertically integrated (2 manufacturers)
- Mix: one manufacturer with a private retailer, and one manufacturer with vertically integrated company store (3 players)
Each retail outlet has a downward sloping demand curve:
\[ q_i = f_i(p_1,p_2) \]
Under decentralized system (4 players), the Nash equilibrium demand curve is a function of wholesale prices:
\[ q_i^* = g_i (w_1, w_2) \]
More rules:
- Assume 2 retailers respond, but not the competing manufacturer
And unobserved wholesale prices and market is not restrictive, and Nash equilibrium whole prices is still possible.
Under mixed structure , the two retailers compete, and non-integrated firm account for all responses in the market
Under integrated structure , this is a two-person game, where each chooses the retail price
Decision variables are prices (not quantities)
Under what conditions a manufacturer want to have intermediaries
Retail demand functions are assumed to be linear in prices
Demand functions are
\[ q_1' = \mu S [ 1 - \frac{\beta}{1 - \theta} p_1' + \frac{\beta \theta}{1- \theta}p_2'] \]
\[ q_2' = (1- \mu) S [ 1+ \frac{\beta \theta}{1- \theta} p_1' - \frac{\beta}{1- \theta} p_2'] \]
\(0 \le \mu , \theta \le 1; \beta, S >0\)
S is a scale factor, which equals industry demand ( \(q' \equiv q_1' + q_2'\) ) when prices are 0.
\(\mu\) = absolute difference in demand
\(\theta\) = substutability of products (reflected by the cross elasticities), or the ratio of the rate of change of quantity with respect to the competitor’s price to the rate of change of quantity with respect to own price.
\(\theta = 0\) means independent demands (firms are monopolists)
\(\theta \to 1\) means maximally substitutable
3 more conditions:
\[ P = \{ p_1', p_2' | p_i' -m' - s' \ge 0, i = 1,2; (1-\theta) - \beta p_1' \beta \theta p_2' \ge 0, (1- \theta) + \beta \theta p_1' - \beta p_2' \ge 0 \} \]
where \(m', s'\) are fixed manufacturing and selling costs per unit
To have a set of \(P\) , then
\[ \beta \le \frac{1}{m' + s'} \]
and to have industry demand no increase with increases in either price then
\[ \frac{\theta}{1 + \theta} \le \mu \le \frac{1}{1 + \theta} \]
After rescaling, the industry demand is
\[ q = 2 (1- \theta) (p_1+ p_2) \]
When each manufacturer is a monopolist ( \(\theta = 0\) ), it’s twice as profitable for each to sell through its own channel
When demand is maximally affected by the actions of the competing retailers ( \(\theta \to 1\) ), it’s 3 times as profitable to have private dealers.
The breakeven point happens at \(\theta = .708\)
In conclusion, the optimal distribution system depends of the degree of substitubability at the retail level.
Jeuland and Shugan ( 2008 )
Quantity discounts is offered because
Cost-based economies of scale
Demand based - large purchases tend to be more price sensitive
Strategic reason- single sourcing
Channel Coordination (this is where this paper contributes to the literature
K. S. Moorthy ( 1987 )
- Price discrimination - second degree
Geylani, Dukes, and Srinivasan ( 2007 )
Jerath and Zhang ( 2010 )
21.10 Advertising Models
Three types of advertising:
- Informative Advertising: increase overall demand of your brand
- Persuasive Advertising: demand shifting to your brand
- Comparison: demand shifting away from your competitor (include complementary)
n customers distributed uniformly along the Hotelling’s line (more likely for mature market where demand doesn’t change).
\[ U_A = V - p_A - tx \\ U_B = V - p_B - t(1-x) \]
For Persuasive advertising (highlight the value of the product to the consumer):
\[ U_A = A_A V - p_A - tx \]
or increase value (i.e., reservation price).
\[ U_A = \sqrt{Ad_A} V - p_A - tx \]
or more and more customers want the product (i.e., more customers think firm A product closer to what they want)
\[ U_A = V - p_A - \frac{tx}{\sqrt{Ad_A}} \]
Comparison Advertising:
\[ U_A = V - p_A - t\sqrt{Ad_{B}}x \\ U_B = V - p_B - t \sqrt{Ad_A}(1 - x) \]
Find marginal consumers
\[ V - p_A - t\sqrt{Ad_{B}}x = V - p_B - t \sqrt{Ad_A}(1 - x) \]
\[ x = \frac{1}{t \sqrt{Ad_A} + t \sqrt{Ad_B}} (-p_A + p_B + t \sqrt{Ad_A}) \]
then profit functions are (make sure the profit function is concave)
\[ \pi_A = p_A x n - \phi Ad_A \\ \pi_B = p_B (1-x) n - \phi Ad_B \]
\(\phi\) = per unit cost of advertising (e.g., TV advertising vs. online advertising in this case, TV advertising per unit cost is likely to be higher than online advertising per unit cost)
t can also be thought of as return on advertising (traditional Hotelling’s model considers t as transportation cost)
Equilibrium prices conditioned on advertising
\[ \frac{d \pi_A}{p_A} = - \frac{d}{p_A} () \\ \frac{d \pi_B}{p_B} = \frac{d}{p_B} \]
Then optimal pricing solutions are
\[ p_A = \frac{2}{3} t \sqrt{Ad_A} + \frac{1}{3} t \sqrt{Ad_B} \\ p_B = \frac{1}{3} t \sqrt{Ad_A} + \frac{2}{3} t \sqrt{Ad_B} \]
Prices increase with the intensities of advertising (if you invest more in advertising, then you charge higher prices). Each firm price is directly proportional to their advertising, and you will charger higher price when your competitor advertise as well.
Then, optimal advertising (with the optimal prices) is
\[ \frac{d \pi_A}{d Ad_A} \\ \frac{d \pi_B}{d Ad_B} \]
Hence, Competitive equilibrium is
\[ Ad_A = \frac{25 t^2 n^2}{576 \phi^2} \\ Ad_B = \frac{25t^2 n^2}{576 \phi^2} \\ p_A = p_B = \frac{5 t^2 n }{24 \phi} \]
As cost of advertising ( \(\phi\) ), firms spend less on advertising
Higher level of return on advertising ( \(t\) ), firms benefit more from advertising
With advertising in the market, the equilibrium prices are higher than if there were no advertising.
Since colluding on prices are forbidden, and colluding on advertising is hard to notice, firms could potential collude on advertising (e.g., pulsing).
Assumption:
- Advertising decision before pricing decision (reasonable because pricing is earlier to change, while advertising investment is determined at the beginning of each period).
Collusive equilibrium (instead of using \(Ad_A, Ad_B\) , use \(Ad\) - set both advertising investment equal):
\[ Ad_A = Ad_B = \frac{t^2 n^2}{16 \phi^2} > \frac{25t^2 n^2}{576 \phi^2} \]
Hence, collusion can be make advertising investment equilibrium higher, which makes firms charge higher prices, and customers will be worse off. (more reference Aluf and Shy - check Modeling Seminar Folder - Advertising).
Combine both Comparison and Persuasive Advertising
\[ U_A = V - p_A - tx \frac{\sqrt{Ad_B}}{\sqrt{Ad_A}} \\ U_B = V - p_B - t(1-x) \frac{\sqrt{Ad_A}}{\sqrt{Ad_B}} \]
Informative Advertising
- Increase number of n customers (more likely for new products where the number of potential customers can change)
How do we think about customers, how much to consume. People consume more when they have more availability, and less when they have less in stock ( Ailawadi and Neslin 1998 )
Villas-Boas ( 1993 )
- Under monopoly, firms would be better off to pulse (i.e., alternate advertising between a minimum level and efficient amount of advertising) because of the S-shaped of the advertising response function.
Model assumptions:
- The curve of the advertising response function is S-shaped
- Markov strategies: what firms do in this period depends on what might affect profits today or in the future (independent of the history)
Propositions:
- “If the loss from lowering the consideration level is larger than the efficient advertising expenditures, the unique Markov perfect equilibrium is for firms to advertise, whatever the consideration levels of both firms are.”
Nelson ( 1974 )
Quality of a brand is determined before a purchase of a brand is “search qualities”
Quality that is not determined before a purchase is “experience qualities”
Brand risks credibility if it advertises misleading information, and pays the costs of processing nonbuying customers
There is a reverse association between quality produced and utility adjusted price
Firms that want to sell more advertise more
Firms advertise to their appropriate audience, i.e., “those whose tastes are best served by a given brand are those most likely to see an advertisement for that brand” (p. 734).
Advertising for experience qualities is indirect information while advertising for search qualities is direct information . (p. 734).
Goods are classified based on quality variation (i.e., whether the quality variation was based on searhc of experience).
3 types of goods
experience durable
experience nondurable
search goods
Experience goods are advertised more than search goods because advertisers increase sales via increasing the reputability of the sellers.
The marginal revenue of advertisement is greater for search goods than for experience goods (p. 745). Moreover, search goods will concentrate in newspapers and magazines while experience goods are seen on other media.
For experience goods, WOM is better source of info than advertising (p. 747).
Frequency of purchase moderates the differential effect of WOM and advertising (e.g., for low frequency purchases, we prefer WOM) (p. 747).
When laws are moderately enforced, deceptive advertising will happen (too little law, people would not trust, too much enforcement, advertisers aren’t incentivized to deceive, but moderate amount can cause consumers to believe, and advertisers to cheat) (p. 749). And usually experience goods have more deceptive advertising (because laws are concentrated here).
Iyer, Soberman, and Villas-Boas ( 2005 )
Firms advertise to their targeted market (those who have a strong preference for their products) than competitor loyalists, which endogenously increase differentiation in the market, and increases equilibrium profits
Targeted advertising is more valuable than target pricing. Target advertising leads to higher profits regardless whether firms have target pricing. Target pricing increased competition for comparison shoppers (no improvement in equilibrium profits). (p. 462 - 463).
Comparison shoppers size:
\[ s = 1 - 2h \]
where \(h\) is the market size of each firm’s consumers (those who prefer to buy product from that firm). Hence, \(h\) also represents the differentiation between the two firms
See table 1 (p. 469).
\(A\) is the cost for advertising the entire market
\(r\) is the reservation price
Yuxin Chen et al. ( 2009 )
Combative vs. constructive advertising
Informative complementary and persuasive advertising
Informative: increase awareness, reduce search costs, increase product differentiation
Complementary (under comparison): increase utility by signaling social prestige
Persuasive: decrease price sensitivity (include combative)
Consumer response moderates the effect of combative adverting on price competition:
It decreases price competition
It increases price competition when (1) consumers preferences are biased (firms that advertise have their products favored by the consumers), (2) disfavor firms can’t advertise and only respond with price. because advertising war leads to a price war (when firms want to increase their own profitability while collective outcome is worse off).
21.11 Product Differentiation
Horizontal differentiation: different consumers prefer different products
Vertical differentiation: where you can say one good is “better” than the other.
Characteristics approach: products are the aggregate of their characteristics.
21.12 Product Quality, Durability, Warranties
Horizontal Differentiation
\[ U = V -p - t (\theta - a)^2 \]
Vertical Differentiation
\[ U_B = \theta s_B - p_B \\ U_A = \theta s_A - p_A \]
Assume that product B has a higher quality
\(\theta\) is the position of any consumer on the vertical differentiation line.
When \(U_A < 0\) then customers would not buy
Point of indifference along the vertical quality line
\[ \theta s_B - p_B = \theta s_A - p_A \\ \theta(s_B - s_A) = p_B - p_A \\ \bar{\theta} = \frac{p_B - p_A}{s_B - s_A} \]
If \(p_B = p_A\) for every \(\theta\) , \(s_B\) is preferred to \(s_A\)
\[ \pi_A = (p_A - c s_A^2) (Mktshare_A) \\ \pi_B = (p_B - cs_B^2) (Mktshare_B) \\ U_A = \theta s_A - p_A = 0 \\ \bar{\theta}_2 = \frac{p_A}{s_A} \]
- Wauthy ( 1996 )
\(\frac{b}{a}\) = such that market is covered, then
\[ 2 \le \frac{b}{a} \le \frac{2s_2 + s_1}{s_2 - s_1} \]
for the market to be covered
In vertical differentiation model, you can’t have both \(\theta \in [0,1]\) and full market coverage.
Alternatively, you can also specify \(\theta \in [1,2]; [1,4]\)
\[ \theta \in \begin{cases} [1,4] & \frac{b}{a} = 4 \\ [1,2] & \frac{b}{a} = 2 \end{cases} \]
Under Asymmetric Information
Adverse Selection: Before contract: Information is uncertain
Moral Hazard: After contract, intentions are unknown to at least one of the parties.
Alternative setup of Akerlof’s (1970) paper
Used cars quality \(\theta \in [0,1]\)
Seller - car of type \(\theta\)
Buyer = WTP = \(\frac{3}{2} \theta\)
Both of them can be better if the transaction occurs because buyer’s WTP for the car is greater than utility received by seller.
- Assume quality is observable (both sellers and buyers do know the quality of the cars):
Price as a function of quality \(p(\theta)\) where \(p(\theta) \in [\theta, 3/2 \theta]\) both parties can be better off
- Assume quality is unobservable (since \(\theta\) is uniformly distributed) (sellers and buyers do not know the quality of the used cars):
\[ E(\theta) = \frac{1}{2} \]
then \(E(\theta)\) for sellers is \(1/2\)
\(E(\theta)\) for buyer = \(3/2 \times 1/2\) = 3/4
then market happens when \(p \in [1/2,3/4]\)
- Asymmetric info (if only the sellers know the quality)
Seller knows \(\theta\)
Buyer knows \(\theta \sim [0,1]\)
From seller perspective, he must sell at price \(p \ge \theta\) and
From buyer perspective, quality of cars on sale is between \([0, p]\) . Then, you will have a smaller distribution than \([0,1]\)
If \(E[(\theta) | \theta \le p] = 0.5 p\)
Buyers’ utility is \(3/4 p\) but the price he has to pay is \(p\) (then market would not happen)
21.12.1 Akerlof ( 1970 )
- This paper is on adverse selection
- The relationship between quality and uncertainty (in automobiles market)
- 2 x 2 (used vs. new, good vs. bad)
\(q\) = probability of getting a good car = probability of good cars produced
and \((1-q)\) is the probability of getting a lemon
Used car sellers have knowledge about the probability of the car being bad, but buyers don’t. And buyers pay the same price for a lemon as for a good car (info asymmetry).
Gresham’s law for good and bad money is not transferable (because the reason why bad money drives out goo d money because of even exchange rate, while buyers of a car cannot tell if it is good or bad).
21.12.1.1 Asymmetrical Info
Demand for used automobiles depends on price quality:
\[ Q^d = D(p, \mu) \]
Supply for used cars depends on price
\[ S = S(p) \]
and average quality depends on price
\[ \mu = \mu(p) \]
In equilibrium
\[ S(p) = D(p, \mu(p)) \]
At no price will any trade happen
Assume 2 groups of graders:
First group: \(U_1 = M = \sum_{i=1}^n x_i\) where
\(M\) is the consumption of goods other than cars
\(x_i\) is the quality of the i-th car
n is the number of cars
Second group: \(U_2 = M + \sum_{i=1}^n \frac{3}{2} x_i\)
Group 1’s income is \(Y_1\)
Group 2’s income is \(Y_2\)
Demand for first group is
\[ \begin{cases} D_1 = \frac{Y_1}{p} & \frac{\mu}{p}>1 \\ D_1 = 0 & \frac{\mu}{p}<1 \end{cases} \]
Assume we have uniform distribution of automobile quality.
Supply offered by first group is
\[ S_2 = \frac{pN}{2} ; p \le 2 \]
with average quality \(\mu = p/2\)
Demand for second group is
\[ \begin{cases} D_2 = \frac{Y_2}{p} & \frac{3 \mu}{2} >p \\ D_2 = 0 & \frac{3 \mu}{2} < p \end{cases} \]
and supply by second group is \(S_2 = 0\)
Thus, total demand \(D(p, \mu)\) is
\[ \begin{cases} D(p, \mu) = (Y_2 + Y_1) / p & \text{ if } p < \mu \\ D(p, \mu) = (Y_2)/p & \text{ if } \mu < p < 3\mu /2 \\ D(p, \mu) = 0 & \text{ if } p > 3 \mu/2 \end{cases} \]
With price \(p\) , average quality is \(p/2\) , and thus at no price will any trade happen
21.12.1.2 Symmetric Info
Car quality is uniformly distributed \(0 \le x \le 2\)
\[ \begin{cases} S(p) = N & p >1 \\ S(p) = 0 \end{cases} \]
\[ \begin{cases} D(p) = (Y_2 + Y_1) / p & p < 1 \\ D(p) = Y_2/p & 1 < p < 3/2 \\ D(p) = 0 & p > 3/2 \end{cases} \]
\[ \begin{cases} p = 1 & \text{ if } Y_2< N \\ p = Y_2/N & \text{ if } 2Y_2/3 < N < Y_2 \\ p = 3/2 & \text{ if } N < 2 Y_2 <3 \end{cases} \]
This model also applies to (1) insurance case for elders (over 65), (2) the employment of minorities, (3) the costs of dishonesty, (4) credit markets in underdeveloped countries
To counteract the effects of quality uncertainty, we can have
- Brand-name good
- Licensing practices
21.12.2 Spence ( 1973 )
Built on ( Akerlof 1970 ) model
Consider 2 employees:
Employee 1: produces 1 unit of production
Employee 2: produces 2 units of production
We have \(\alpha\) people of type 1, and \(1-\alpha\) people of type 2
Average productivity
\[ E(P) = \alpha + 2( 1- \alpha) = 2- \alpha \]
You can signal via education.
To model cost of education,
Let E to be the cost of education for type 1
E/2 to be the cost education for type 2
If type 1 signals they are high-quality worker, then they have to go through the education and cost is E, and net utility of type 1 worker
\[ 2 - E < 1 \\ E >1 \]
If type 2 signals they are high-quality worker, then they also have to go through the education and cost is E/2 and net utility of type 2 worker is
\[ 2 - E/2 > 1 \\ E< 2 \]
If we keep \(1 < E < 2\) , then we have separating equilibrium (to have signal credible enough of education )
21.12.3 S. Moorthy and Srinivasan ( 1995 )
Money-back guarantee signals quality
Transaction cost are those the seller or buyer has to pay when redeeming a money-back guarantee
Money-back guarantee does not include product return (buyers have to incur expense), but guarantee a full refund of the purchase price.
If signals are costless, there is no difference between money-back guarantees and price
But signal are costly,
Under homogeneous buyers, low-quality sellers cannot mimic high-quality sellers’ strategy (i.e., money-back guarantee)
Under heterogeneous buyers,
when transaction costs are too high, the seller chooses either not to use money-back guarantee strategy or signal through price.
When transaction costs are moderate, there is a critical value of seller transaction costs where
below this point, the high-quality sellers’ profits increase with transaction costs
above this point, the high-quality sellers’ profits decrease with transaction costs
Uninformative advertising (“money-burning”) is defined as expenditures that do not affect demand directly. is never needed
Moral hazard:
- Consumers might exhaust consumption within the money-back guarantee period
Model setup
| High-quality sellers (\(h\)) | Low-quality sellers (\(l\)) | |
|---|---|---|
| Cost \(c_h > c_l\) | \(c_h\) | \(c_l\) |
21.13 Bargaining
Abhinay Muthoo - Bargaining Theory with Applications (1999) (check books folder)
Josh Nash - Nash Bargaining (1950)
Allocation of scare resources
| Buyers & Sellers | Type |
|---|---|
| Many buyers & many sellers | Traditional markets |
| Many buyers & one seller | Auctions |
| One buyer & one seller | Bargaining |
Allocations of
Determining the share before game-theoretic bargaining
Use a judge/arbitrator
Meet-in-the-middle
Forced Final: If an agreement is not reached, one party will use take it or leave it
Art: Negotiation
Science: Bargaining
Game theory’s contribution: to the rules for the encounter
Area that is still fertile for research
21.13.1 Non-cooperative
Outline for non-cooperative bargaining
Take-it-or-leave-it Offers
Bargain over a cake
If you accept, we trade
If you reject, no one eats
Under perfect info, there is a simple rollback equilibrium
In general, bargaining takes on a “take-it-or-counteroffer” procedure
If time has value, both parties prefer to trade earlier to trade later
- E.g., labor negotiations - later agreements come at a price of strikes, work stoppages
Delays imply less surplus left to be shared among the parties
Two-stage bargaining
I offer a proportion, \(p\) , of the cake to you
If rejected, you may counteroffer (and \(\delta\) of the cake melts)
In the first period: 1-p, p
In second period: \((1-\delta) (1-p),(1-\delta)p\)
Since period 2 is the final period, this is just like a take-it-or-leave-it offer
- You will offer me the smallest piece that I will accept, leaving you with all of \(1-\delta\) and leaving me with almost 0
Rollback: then in the first period: I am better off by giving player B more than what he would have in period 2 (i.e., give you at least as much surplus)
You surplus if you accept in the first period is \(p\)
Accept if: your surplus in first period greater than your surplus in second period \(p \ge 1 - \delta\)
IF there is a second stage, you get \(1 - \delta\) and I get 0
You will reject any offer in the first stage that does not offer you at least \(1 - \delta\)
In the first period, I offer you \(1 - \delta\)
Note: the more patient you are (the slower the cake melts) the more you receive now
Whether first or second mover has the advantage depends on \(\delta\) .
If \(\delta\) is high (melting fast), then first mover is better.
If \(\delta\) is low (melting slower), then second mover is better.
Either way - if both players think, agreement would be reached in the first period
In any bargaining setting, strike a deal as early as possible.
Why doesn’t this happen in reality?
reputation building
lack of information
Why bargaining doesn’t happen quickly? Information asymmetry
- Likelihood of success (e.g., uncertainty in civil lawsuits)
Rules of the bargaining game uniquely determine the bargain outcome
which rules are better for you depends on patience, info
What is the smallest acceptable piece? Trust your intuition
delays are always less profitable: Someone must be wrong
Non-monetary Utility
each side has a reservation price
- LIke in civil suit: expectation of wining
The reservation price is unknown
probabilistically determine best offer
but - probability implies a chance that non bargain will take place
Company negotiates with a union
Two types of bargaining:
Union makes a take-it-or-leave-it offer
Union makes a n offer today. If it’s rejected, the Union strikes, then makes another offer
- A strike costs the company 10% of annual profits.
Probability that the company is “highly profitable”, ie., 200k is \(p\)
If offer wage of $150k
Definitely accepted
Expected wage = $150K
If offer wage of $200K
Accepted with probability \(p\)
Expected wage = $200k(p)
\(p = .9\) (90% chance company is highly profitable
best offer: ask for $200K wage
Expected value of offer: \(.9 *200= 180\)
\(p = .1\) (10% chance company is highly profitable
Expected value of offer: \(.1 *200= 20\)
If ask for $10k, get $150k
not worth the risk to ask for more
If first-period offer is rejected: A strike costs the company 10% of annual profits
Strike costs a high-value company more than a low value company
Use this fact to screen
What if the union asks for $170k in the first period?
Low profit firms ($150k) rejects - as can’t afford to take
HIgh profit firm must guess what will happen if it rejects
Best case: union strikes and then asks for only $140k (willing to pay for some cost of strike), but not all)
In the mean time: strike cost the company $20K
High-profit firm accepts
Separating equilibrium
only high-profit firms accept the first period
If offer is rejected, Union knows that it is facing a low-profit firm
Ask for $140k
What’s happening
Union lowers price after a rejection
Looks like giving in
looks like bargaining
Actually, the union is screening its bargaining partner
Different “types” of firms have different values for the future
Use these different values to screen
Time is used as a screening device
21.13.2 Cooperative
two people diving cash
If they do not agree, they each get nothing
They cant divide up more than the whole thing
21.13.3 Nash ( 1950 )
Bargaining, bilateral monopoly (nonzero-sum two -person game).
Non action taken by one individual (without the consent of the other) can affect the other’s gain.
Rational individuals (maximize gain)
Full knowledge: tastes and preferences are known
Transitive Ordering: \(A>C\) when \(A>B\) , \(B>C\) . Also related to substitutability if two events are of equal probability
Continuity assumption
Properties:
\(u(A) > u(B)\) means A is more desirable than B where \(u\) is a utility function
Linearity property: If \(0 \le p \le 1\) , then \(u(pA + (1-p)B) = pu(A) + (1-p)u(B)\)
- For two person: \(p[A,B] + (1-p)[C,D] = [pA - (1-p)C, pB + (1-p)D]\)
Anticipation = \(p A - (1-p) B\) where
\(p\) is the prob of getting A
A and B are two events.
\(u_1, u_2\) are utility function
\(c(s)\) is the solution point in a set S (compact, convex, with 0)
If \(\alpha \in S\) s.t there is \(\beta \in S\) where \(u_1(\beta) > u_2(\alpha)\) and \(u_2(\beta) > u_2(\alpha)\) then \(\alpha \neq c(S)\)
- People try to maximize utility
If \(S \in T\) , c(T) is in S then \(c(T) = c(S)\)
If S is symmetric with respect to the line \(u_1 = u_2\) , then \(c(S)\) is on the line \(u_1 = u_2\)
- Equality of bargaining
21.13.4 Iyer and Villas-Boas ( 2003 )
- Presence of a powerful retailer (e.g., Walmart) might be beneficial to all channel members.
21.13.5 Desai and Purohit ( 2004 )
2 customers segment: hagglers, nonhagglers.
When the proportion of nonhagglers is sufficient high, a haggling policy can be more profitable than a fixed-price policy
21.14 Pricing and Search Theory
21.14.1 varian and purohit ( 1980 ).
From Stigler’s seminar paper ( Stiglitz and Salop 1982 ; Salop and Stiglitz 1977 ) , model of equilibrium price dispersion is born
Spatial price dispersion: assume uninformed and informed consumers
- Since consumers can learn from experience, the result does not hold over time
Temporal price dispersion: sales
This paper is based on
Stiglitz: assume informed (choose lowest price store) and uninformed consumers (choose stores at random)
Shilony ( Shilony 1977 ) : randomized pricing strategies
\(I >0\) is the number of informed consumers
\(M >0\) is the number of uninformed consumers
\(n\) is the number of stores
\(U = M/n\) is the number of uninformed consumers per store
Each store has a density function \(f(p)\) indicating the prob it charges price \(p\)
Stores choose a price based on \(f(p)\)
Succeeds if it has the lowest price among n prices, then it has \(I + U\) customers
Fails then only has \(U\) customers
Stores charge the same lowest price will share equal size of informed customers
\(c(q)\) is the cost curve
\(p^* = \frac{c(I+U)}{(I+U}\) is the average cost with the maximum number of customers a store can get
Prop 1: \(f(p) = 0\) for \(p >r\) or \(p < p^*\)
Prop 2: No symmetric equilibrium when stores charge the same price
Prop 3: No point masses in the equilibrium pricing strategies
Prop 4: If \(f(p) >0\) , then
\[ \pi_s(p) (1-F(p))^{n-1} + \pi_f (p) [1-(1-F(p))^{n-1}] =0 \]
Prop 5: \(\pi_f (p) (\pi_f(p) - \pi_s (p))\) is strictly decreasing in \(p\)
Prop 6: \(F(p^* _ \epsilon) >0\) for any \(\epsilon> 0\)
Prop 7: \(F(r- \epsilon) <1\) for any \(\epsilon > 0\)
Prop 8: No gap \((p_1, p_2)\) where \(f(p) \equiv 0\)
Decision to be informed can be endogenous, and depends on the “full price” (search costs + fixed cost)
21.14.2 Lazear ( 1984 )
Retail pricing and clearance sales
Goods’ characteristics affect pricing behaviors
Market’s thinness can affect price volatility
Relationship between uniqueness of a goods and its price
Price reduction policies as a function of shelf time
Single period model
\(V\) = the price of the only buyer who is willing to purchase the product
\(f(V)\) is the density of V (firm’s prior)
\(F(V)^2\) is its distribution function
Firms try to
\[ \underset{R}{\operatorname{max}} R[1 - F(R)] \]
where \(R\) is the price
\(1 - F(R)\) is the prob that \(V > R\)
Assume \(V\) is uniform \([0,1]\) then
\(F(R) = R\) so that the optimum is \(R = 0.5\) with expected profits of \(0.25\)
Two-period model
Failures in period 1 implies \(V<R_1\) .
Hence, based on Bayes’ theorem, the posterior distribution in period 2 is \([0, R_1]\)
\(F_2(V) = V/R_1\) (posterior distribution)
\(R_1\) affect (1) sales in period 1, (2) info in period 2
Then, firms want to choose \(R_1, R_2\) .Firms try to
\[ \underset{R_1, R_2}{\operatorname{max}} R_1[1 - F(R_1)] + R_2 [1-F_2(R_2)]F(R_1) \]
Then, in period 2, the firms try to
\[ \underset{R_2}{\operatorname{max}} R_2[1 - F_2(R_2)] \]
Based on Bayes’ Theorem
\[ F_2(R_2) = \begin{cases} F(R_2)/ F(R_1) & \text{for } R_2 < R_1 \\ 1 & \text{otherwise} \end{cases} \]
Due to FOC, second period price is always lower than first price price
Expected profits are higher than that of one-period due to higher expected probability of a sale in the two-period problem.
But this model assume
no brand recognition
no contagion or network effects
In thin markets and heterogeneous consumers
we have \(N\) customers examine the good with the prior probability \(P\) of being shoppers, and \(1-P\) being buyers who are willing to buy at \(V\)
There are 3 types of people
- customers = all those who inspect the good
- buyers = those whose value equal \(V\)
- shoppers = those who value equal \(0\)
An individual does not know if he or she is a buyer or shopper until he or she is a customer (i.e., inspect the goods)
Then, firms try to
\[ \begin{aligned} \underset{R_1, R_2}{\operatorname{max}} & R_1(\text{prob sale in 1}) + R_2 (\text{Posterior prob sale in 2})\times (\text{Prob no sale in 1}) \\ & R_1 \times (- F(R_1))(1-P^N) + R_2 \{ (1-F_2(R_2))(1- P^N) \} \times \{ 1 - [(1 - F(R_1))(1-P^N)] \} \end{aligned} \]
Based on Bayes’ Theorem, the density for period 2 is
\[ f_2(V) = \begin{cases} \frac{1}{R_1 (1- P^N) + P^N} \text{ for } V \le R_1 \\ \frac{P^N}{R_1 (1- P^N) + P^N} \text{ for } V > R_1 \end{cases} \]
Conclusion:
As \(P^N \to 1\) (almost all customers are shoppers), there is not much info to be gained. Hence, 2-period is no different than 2 independent one-period problems. Hence, the solution in this case is identical to that of one-period problem.
When \(P^N\) is small, prices start higher and fall more rapid as time unsold increases
When \(P^N \to 1\) , prices tend to be constant.
\(P^N\) can also be thought of as search cost and info.
Observable Time patterns of price and quantity
Pricing is a function of
The number of customers \(N\)
The proportion of shoppers \(P\)
The firm’s beliefs about the market (parameterized through the prior on \(V\) )
Markets where prices fall rapidly as time passes, the probability that the good will go unsold is low.
Goods with high initial price are likely to sell because high initial price reflects low \(P^N\) - low shoppers
Heterogeneity among goods
The more disperse prior leads to a higher expected price for a given mean. And because of longer time on shelf, expected revenues for such a product can be lower.
Fashion, Obsolescence, and discounting the future
The more obsolete, the more anxious is the seller
Goods that are “classic”, have a higher initial price, and its price is less sensitive to inventory (compared to fashion goods)
Discounting is irrelevant to the pricing condition due to constant discount rate (not like increasing obsolescence rate)
For non-unique good, the solution is identical to that of the one-period problem.
Simple model
Customer’s Valuation \(\in [0,1]\)
Firm’s decision is to choose a price \(p\) (label - \(R_1\) )
One-period model
Buy if \(V >R_1\) prob = \(1-R_1\)
Not buy if \(V<R_1\) probability = \(R_1\)
\(\underset{R_1}{\operatorname{max}} [R_1][1-R_1]\) hence, FOC \(R_1 = 1/2\) , then total \(\pi = 1/2-(1/2)^2 = 1/4\)
Two prices \(R_1, R_2\)
\(R_1 \in [0,1]\)
\(R_2 \in [0, R_1]\)
\[ \underset{R_1}{\operatorname{max}} [R_1][1-R_1] + R_2 (1 - R_2)(R_1) \]
\[ \underset{R_1}{\operatorname{max}} [R_2][\frac{R_1 - R_2}{R_1}] \]
FOC \(R_2 = R_1/2\)
\[ \underset{R_1}{\operatorname{max}} R_1(1-R_1) + \frac{R_1}{2}(1 - \frac{R_1}{2}) (R_1) \]
FOC: \(R_1 = 2/3\) then \(R_2 = 1/3\)
\(N\) customers
Each customer could be a
shopper with probability p with \(V <0\)
buyer with probability \(1-p\) with \(V > \text{price}\)
Modify equation 1 to incorporate types of consumers
\[ R_1(1 - R_1)(1- p^N) + R_2 (1- R_2) R_1 (1-p^N) [ 1 - (1-R_1)(1-p^N)] \]
Reduce costs by
Economy of scale \(c(\text{number of units})\)
Economy of scope \(c(\text{number of types of products})\) (typically, due to the transfer of knowledge)
Experience effect \(c(\text{time})\) (is a superset of economy of scale)
Lal and Sarvary ( 1999 )
Conventional idea: lower search cost (e.g., Internet) will increase price competition.
Demand side: info about product attributes:
digital attributes (those can be communicated via the Internet)
nondigital attributes (those can’t)
Supply side: firms have both traditional and Internet stores.
Monopoly pricing can happen when
high proportion of Internet users
Not overwhelming nondigital attributes
Favor familiar brands
destination shopping
Monopoly pricing can lead to higher prices and discourage consumer from searching
Stores serve as acquiring tools, while Internet maintain loyal customers.
Kuksov ( 2004 )
For products that cannot be changed easily (design),lower search costs lead to higher price competition
For those that can be easily changed, lower search costs lead to higher product differentiation, which in turn decreases price competition , lower social welfare, higher industry profits.
( Salop and Stiglitz 1977 )
21.15 Pricing and Promotions
Extensively studied
Issue of Everyday Low price vs Hi/Lo pricing
Short-term price discounts
offering trade-deals
consumer promotions
shelf-price discounts (used by everybody)
cents-off coupons (some consumers whose value of time is relatively low)
Loyalty is similar to inform under analytic modeling:
Uninformed = loyal
Informed = non-loyal
30 years back, few companies use price promotions
Effects of Short-term price discounts
measured effects (84%) ( Gupta 1988 )
Brand switching (14%)
purchase acceleration (2%)
quantity purchased
elasticity of ST price changes is an order of magnitude higher
Other effects:
general trial (traditional reason)
encourages consumers to carry inventory hence increase consumption
higher sales of complementary products
small effect on store switching
Asymmetric effect (based on brand strength) (bigger firms always benefit more)
- expect of store brands
Negative Effects
Expectations of future promotions
Lowering of Reference Price
Increase in price sensitivity
Post-promotional dip
Trade Discounts
Short-term discounts offered to the trade:
Incentivize the trade to push our product
gets attention of sales force
Disadvantages
might not be passed onto the consumer
trade forward buys (hurts production plans)
hard to forecast demand
trade expects discounts in the future (cost of doing business)
Scanback can help increase retail pass through (i.e., encourage retailers to have consumer discounts)
Determinants of pass through
Higher when
Consumer elasticity is higher
promoting brand is stronger
shape of the demand function
lower frequency of promotions
(Online) Shelf-price discounts ( Raju, Srinivasan, and Lal 1990 )
- If you are a stronger brand you can discount infrequently because the weaker brands cannot predict when the stronger brands will promote. Hence, it has to promote more frequently
Little over 1% get redeemed each year
The ability of cents-off coupons to price distribution has reduced considerably because of their very wide availability
Sales increases required to make free-standing-insert coupons profitable are not attainable
Coupon Design
Expiration dates
- Long vs short expiration dates: Stronger brands should have shorter windows (because a lot more of your loyalty customer base will utilize the coupons).
Method of distribution
In-store (is better)
Through the package
Targeted promotions
Package Coupons acquisition and retention trade-offs
3 types of package coupons:
Peel-off (lots more use the coupons) lowest profits for the firm
in-packs (fewer customers will buy the products in the first period)
on-packs (customers buy the products and they redeem in the next period) best approach
Trade and consumer promotion are necessary
Consumer promotion (avoid shelf price discount/news paper coupons, use package coupons
strong interaction between advertising and promotion (area for more research)
3 degrees price discrimination
- First-degree: based on willingness to pay
- Second-degree: based on quantity
- Third-degree: based on memberships
- Fourth-degree: based on cost to serve
21.15.1 Narasimhan ( 1988 )
Marketing tools to promote products:
Advertising
Trade promotions
Consumer promotions
Pricing promotions:
Price deals
Cents-off labels
Brand loyalty can help explain the variation in prices (in competitive markets)
Firms try to make optimal trade-off between
attracting brand switchers
loss of profits from loyal customers.
Deviation from the maximum price = promotion
Firms with identical products, and cost structures (constant or declining). Non-cooperative game.
Same reservation price
Three consumer segments:
Loyal to firm 1 with size \(\alpha_1 (0<\alpha_1<1)\)
Loyal to firm 2 with size \(\alpha_2(0 < \alpha_2 < \alpha_1)\) (asymmetric firm)
Switchers with size \(\beta (0 < \beta = 1 - \alpha_1 - \alpha_2)\)
Costless price change, no intertemporal effects (in quantity or loyalty)
To model \(\beta\) either
- \(d \in (-b, a)\) is switch cost (individual parameter)
\[ \begin{cases} \text{buy brand 1} & \text{if } P_1 \le P_2 - d \\ \text{buy brand 2} & \text{if } P_1 > P_2 - d \end{cases} \]
- Identical switchers (same d)
- \(d = 0\) (extremely price sensitive)
For case 1, there is a pure strategy, while case 2 and 3 have no pure strategies, only mixed strategies
Details for case 3:
Profit function
\[ \Pi_i (P_i, P_j) = \alpha_i P_i + \delta_{ij} \beta P_i \]
\[ \delta_{ij} = \begin{cases} 1 & \text{ if } P_i < P_j \\ 1/2 & \text{ if } P_i = P_j \\ 0 & \text{ if } P_i > P_j \end{cases} \]
and \(i = 1,2, i \neq j\)
Prop 1: no pure Nash equilibrium
Mixed Strategy profit function
\[ \Pi_i (P_i) = \alpha_i P_i + Prob(P_j > P_i) \beta P_i + Prob (P_j = P_i) \frac{\beta}{2} P_i \]
where \(P_i \in S_i^*, i \neq j; i , j = 1, 2\)
Then the expected profit functions of the two-player game is
\[ \underset{F_i}{\operatorname{max}} E(\Pi_i) = \int \Pi_i (P_i) d F_i (P_i) \]
\(P_i \in S_i^*\)
\[ \Pi_i \ge \alpha_i r \\ \int dF_i (P_i) = 1 \\ P_i \in S_i^* \]
21.15.2 Balachander, Ghosh, and Stock ( 2010 )
- Bundle discounts can be more profitable than price promotions (in a competitive market) due to increased loyalty (which will reduce promotional competition intensity).
21.15.3 Goić, Jerath, and Srinivasan ( 2011 )
Cross-market discounts, purchases in a source market can get you a price discounts redeemable in a target market.
- Increase prices and sales in the source market.
21.16 Market Entry Decisions and Diffusion
Peter N. Golder and Tellis ( 1993 )
Peter N. Golder and Tellis ( 2004 )
Boulding and Christen ( 2003 )
Van den Bulte and Joshi ( 2007 )
21.17 Principal-agent Models and Salesforce Compensation
21.17.1 gerstner and hess ( 1987 ), 21.17.2 basu et al. ( 1985 ), 21.17.3 raju and srinivasan ( 1996 ).
Compare to ( Basu et al. 1985 ) , basic quota plan is superior in terms of implementation
Different from ( Basu et al. 1985 ) , basic quota plan has
- Shape-induced nonoptimality: not a general curvilinear form
- Heterogeneity-induced nonoptimality: common rate across salesforce
However, only 1% of cases in simulation shows up with nonoptimality. Hence, minimal loss in optimality
Basic quota plan is a also robust against changes in
salesperson switching territory
territorial changes (e.g., business condition)
Heterogeneity stems from
Salesperson: effectiveness, risk level, disutility for effort, and alternative opportunity
Territory: Sales potential and volatility
Adjusting quotas can accommodate the heterogeneity
To assess nonoptimality, following Basu and Kalyanaram ( 1990 )
Moral hazard: cannot assess salesperson’s true effort.
The salesperson reacts to the compensation scheme by deciding on an effort level that maximizes his overall utility, i.e., the expected utility from the (stochastic) compensation minus the effort distuility.
Firm wants to maximize its profit
compensation is greater than saleperson’s alternative.
Dollar sales \(x_i \sim Gamma\) (because sales are non-negative and standard deviation getting proportionately larger as the mean increases) with density \(f_i(x_i|t_i)\)
Expected sales per period
\[ E[x_i |t_i] = h_i + k_i t_i , (h_i > 0, k_i >0) \]
- \(h_i\) = base sales level
- \(k_i\) = effectiveness of effort
and \(1/\sqrt{c}\) = uncertainty in sales (coefficient of variation) = standard deviation / mean where \(c \to \infty\) means perfect certainty
salesperson’s overall utility
\[ U_i[s_i(x_i)] - V_i(t_i) = \frac{1}{\delta_i}[s_i (x_i)]^{\delta_i} - d_i t_i^{\gamma_i} \] where
- \(0 < \delta_i <1\) (greater \(\delta\) means less risk-averse salesperson)
- \(\gamma_i >1\) (greater \(\gamma\) means more effort)
- \(V_i(t_i) = d_i t_i^{\gamma_i}\) is the increasing disutility function (convex)
21.17.4 Lal and Staelin ( 1986 )
A menu of compensation plans (salesperson can select, which depends on their own perspective)
Proposes conditions when it’s optimal to offer a menu
Under ( Basu et al. 1985 ) , they assume
Salespeople have identical risk characteristics
identical reservation utility
identical information about the environment
When this paper relaxes these assumptions, menu of contract makes sense
If you cannot distinguish (or have a selection mechanisms) between high performer and low performer, a menu is recommended. but if you can, you only need 1 contract like ( Basu et al. 1985 )
21.17.5 Simester and Zhang ( 2010 )
21.18 branding.
Wernerfelt ( 1988 )
- Umbrella branding
W. Chu and Chu ( 1994 )
retailer reputation
21.19 Marketing Resource Allocation Models
This section is based on ( Mantrala, Sinha, and Zoltners 1992 )
21.19.1 Case study 1
Concave sales response function
- Optimal vs. proportional at different investment levels
- Profit maximization perspective of aggregate function
\[ s_i = k_i (1- e^{-b_i x_i}) \]
- \(s_i\) = current-period sales response (dollars / period)
- \(x_i\) = amount of resource allocated to submarket i
- \(b_i\) = rate at which sales approach saturation
- \(k_i\) = sales potential
Allocation functions
Fixed proportion
\(R_i\) = Investment level (dollars/period)
\(w_i\) = fixed proportion or weights
\[ \hat{x}_i = w_i R; \\ \sum_{t=1}^2 w_t = 1; 0 < w_t < 1 \]
Informed allocator
- optimal allocations via marginal analysis (maximize profits)
\[ max C = m \sum_{i = 1}^2 k_i (1- e^{-b_i x_i}) \\ x_1 + x_2 \le R; x_i \ge 0 \text{ for } i = 1,2 \\ x_1 = \frac{1}{(b_1 + b_2)(b_2 R + \ln(\frac{k_1b_1}{k_2b_2})} \\ x_2 = \frac{1}{(b_1 + b_2)(b_2 R + \ln(\frac{k_2b_2}{k_1b_1})} \]
21.19.2 Case study 2
S-shaped sales response function:
21.19.3 Case study 3
Quadratic-form stochastic response function
- Optimal allocation only with risk averse and risk neutral investors.
21.20 Mixed Strategies
Games with finite number, and finite strategy for each player, there will always be a Nash equilibrium (might not be pure Nash, but always mixed)
Extended game
Suppose we allow each player to choose randomizing strategies
For example, the server might serve left half of the time, and right half of the time
In general, suppose the server serves left a fraction \(p\) of the time
What is the receiver’s best response?
Best Responses
If \(p = 1\) , the receiver should defend to the left
\(p = 0\) , the receiver should defend to the right
The expected payoff to the receiver is
\(p \times 3/4 + (1-p) \times 1/4\) if defending left
\(p \times 1/4 + (1-p) \times 3/4\) if defending right
Hence, she should defend left if
\(p \times 3/4 - (1-p)\times 1/4 > p \times 1/4 + (1-p) \times 3/4\)
We said to defend left whenever
\[ p \times 3/4 - (1-p)\times 1/4 > p \times 1/4 + (1-p) \times 3/4 \]
Server’s Best response
Suppose that the receiver goes left with probability \(q\)
if \(q = 1\) , the server should serve right
If \(q = 0\) , the server should server left
Hence, serve left if \(1/4 \times q + 3/4 \times (1-q) > 3/4\times q + 1/4 \times (1-q)\)
Simplifying, he should serve left if \(q < 1/2\)
Mixed strategy equilibrium:
A mixed strategy equilibrium is a pair of mixed strategies that are mutual best responses
In the tennis example, this occurred when each play chose a 50-50 mixture of left and right
Your best strategy is when you make the option given to your opponent is obsolete.
A player chooses his strategy to make his rival indifferent
A player earns the same expected payoff for each pure strategy chosen with positive probability
Important property: When player’s own payoff form a pure strategy goes up (or down), his mixture does not change.
21.21 Bundling
| Equipment | Installation | |
|---|---|---|
| Customer Type 1 | $8,000 | $2,000 |
| Customer Type 2 | $5,000 | $3,000 |
Say we have equal numbers of type 1 and type 2, then you would like to charge $5,000 for the equipment and $2,000 for installation when considering equipment and installment equally . If you price it separately, then your total profit is 14,000.
But you bundle, you get $16,000.
If we know that bundles work. But we don’t see every company does ti?
Because it depends on the number of type 1 and 2 customers, and negative correlation in willingness to pay .
For example:
Information Products
margin cost is close to 0.
Bundling of info products is very easy
hence always bundle
21.22 Market Entry and Diffusion
Product Life Cycle model
Bass ( 1969 )
Discussion of sales has 2 types
\(p\) = coefficient of innovation (fraction of innovators of the untapped market who buy in that period)
\(q\) = coefficient of imitation (fraction of the interaction which lead to sales in that period)
\(M\) = market potential
\(N(t)\) = cumulative sales till time \(t\)
\(M - N(t)\) = the untapped market
Sales in any time is People buying because of the pure benefits of the product, plus people buy the product after interacting with people who owned the product.
\[ S(t) = p(M- N(t)) + q \frac{N(t)}{M} [M-N(t)] \\ = pM + (q-p) N(t) - \frac{q}{M} [N(t)]^2 \]
one can estimate \(p,q,M\) from data
\(q > p\) (coefficient of imitation > coefficient of innovation) means that you have life cycle (bell-shaped curve)
Previous use
limited databases (PIM and ASSESOR) ( Urban et al. 1986 )
exclusion of nonsurvivors
single-informant self-report
New dataset overcomes these limitations and show 50% of the market pioneers fail, and their mean share is much lower
Early market leaders have greater long-term success and enter on average 13 years after pioneers.
Definitions (p. 159)
- Inventor: firms that develop patent or important technologies in a new product category
- Product pioneer: the first firm to develop a working model or sample in a new product category
- Market pioneer is the first firm to sell in a new product category
- Product category: a group of close substitutes
At the business level, being the leader can give you long-term profit disadvantage from the samples of consumer and industrial goods.
First-to-market leads to an initial profit advantage, which last about 12 to 14 years before becoming long-term disadvantage.
Consumer learning (education), market position (strong vs. weak) and patent protection can moderate the effect of first-mover on profit.
Research on product life cycle (PLC)
Consumer durables typically grow 45 per year over 8 years, then slowdown when sales decline by 15%, and stay below those of the previous peak for 5 years.
Slowdown typically happens when the product penetrates 35-50% of the market
large sales increases (at first) will have larger sales declines (at slowdown).
Leisure-enhancing products tend to have higher growth rate and shorter growth stages than non leisure-enhancing products
Time-saving products have lower growth rates and longer growth stages than non time-saving products
Lower likelihood of slowdown correlates with steeper price reduction, lower penetration, and higher economic growth
A hazard model gives reasonable prediction of the slowdown and takeoff.
Innovations market have two segments:
Influentials: aware of new developments an affect imitators
Imitators: model after influentials.
This market structure is reasonable because it exhibits consistent evidence with the prior research and market (e.g., dip between the early and later parts fo the diffusion curve).
” Erroneously specifying a mixed-influence model to a mixture process where influentials act independently from each other can generate systematic changes in the parameter values reported in earlier research.”
Two-segments model performs better than the standard mixed-influence, the Gamma/Shifted Gompertz, the Weibull-Gamma models, and similar to the Karmeshu-Goswami mixed influence model.
21.23 Principal-Agent Models and Salesforce Compensation
Key Question:
- Ensuring agents exert effort
- Design compensation plans such that workers exert high effort?
Designing contracts:
Effort can be monitored
Monitoring costs are too high
- Manger designs the construct
- manager offers the construct and worker chooses to accept
- Worker decides the extent of effort
- Outcome is observed and wage is given to the worker
Scenario 1 : Certainty
e = effort put in by worker
2 levels of e
- 2 if he works hard
- 0 if he shirks
Reservation utility = 10 (other alternative: can work somewhere else, or private money allows them not to work)
Agent’s Utility
\[ U = \begin{cases} w - e & \text{if he exerts effort e} \\ 10 & \text{if he works somewhere else} \end{cases} \]
Revenue is a function of effort
\[ R(e) = \begin{cases} H & \text{if } e = 2 \\ L & \text{if } e = 0 \end{cases} \]
\(w^H\) = wage if \(R(e) = H\)
\(w^L\) = wage if \(R(e) = L\)
Constraints:
Worker has to participate in this labor market - participation constraint \(w^H - 2 \ge 10\)
Incentive compatibility constraint (ensure that the works always put in the effort and the manager always pay for the higher wage): \(w^H - 2 \ge w^L -0\)
\[ w^H = 12 \\ w^L = 10 \]
Thus, contract is simple because of monitoring
Scenario 2 : Under uncertainty
\[ R(2) = \begin{cases} H & \text{w/ prob 0.8} \\ L & \text{w/ prob 0.2} \end{cases} \\ R(0) = \begin{cases} H & \text{w/ prob 0.4} \\ L & \text{w/ prob 0.6} \end{cases} \]
Agent Utility
\[ U = \begin{cases} E(w) - e & \text{if effort e is put} \\ 10 & \text{if they choose outside option} \end{cases} \]
Participation Constraint: \(0.8w^H + 0.2w^L -2 \ge 10\)
Incentive compatibility constraint: \(0.8w^H + 0.2w^L - 2 \ge 0.4 w^H + 0.6w^L - 0\)
\[ w^H = 13 \\ w^L = 8 \]
Expected wage bill that the manager has to pay:
\[ 13\times 0.8 + 8 \times 0.2 = 12 \]
Hence, the expected money the manager has to pay is the same for both cases (certainty vs. uncertainty)
Scenario 3 : Asymmetric Information
Degrees of risk aversion
Manger perspective
\[ R(2) = \begin{cases} H & \text{w/ prob 0.8} \\ L & \text{w/ prob 0.2} \end{cases} \]
Worker perspective (the number for worker is always lower, because they are more risk averse, managers are more risk neural) (the manager also knows this).
\[ R(2) = \begin{cases} H & \text{w/ prob 0.7} \\ L & \text{w/ prob 0.3} \end{cases} \]
Participation Constraint
\[ 0.7w^H + 0.3w^L - 2 \ge 10 \]
Incentive Compatibility Constraint
\[ 0.6 w^H + 0.3 w^L - 2 \ge 0.4 w^H + 0.6 w^L - 0 \]
(take R(0) from scenario 2)
\[ 0.7 w^H + 0.3 w^L = 12 \\ 0.3w^H - 0.3w^L = 2 \]
\[ w^H = 14 \\ w^L = 22/3 \]
Expected wage bill for the manager is
\[ 14 * 0.8 + 22/3*0.2 = 12.66 \]
Hence, expected wage bill is higher than scenario 2
Risk aversion from the worker forces the manager to pay higher wage
| Salesperson | |||
|---|---|---|---|
| Risk neutral | Risk averse | ||
| Observable | Any mix desired effort | All salary Desired effort | |
| Not observable | All commission Desired effort | Specific mix (S+C) Salesperson shirks |
Grossman and Hart ( 1986 )
- landmark paper for principal agent model
21.23.1 Basu et al. ( 1985 )
Types of compensation plan:
Independent of salesperson’s performance (e.g., salary only)
Partly dependent on output (e.g., salary with commissions)
In comparison to others (e.g., sales contests)
Options for salesperson to choose the compensation plan
In the first 2 categories, the 3 major schemes:
- Straight salary
- Straight commissions
- Combination of base salary and commission
| Compensation Type | Best when | Limitation |
|---|---|---|
| Straight salary | Long-term objective Hard to measure performance | Less effort |
| Straight commission | Easy-to-measure performance | Effort-reward ratio is emphasized High risk (uncertainty) to the salesperson |
| Combination |
Dimensions that affect the proportion of salary tot total pay (p. 270, table 1)
Previous research assumes deterministic relationship between sales and effort, but this study says otherwise (stochastic relationship between sales and effort).
Firm: Risk neutral: maximize expected profits
Salesperson: Risk averse . Hence, diminishing marginal utility for income \(U(s) \ge 0; U'(s) >0, U''(s) <0\)
Expected utility of the salesperson for this job > alternative
Utility function of the salesperson: additively separable: \(U(s) - V(t)\) where \(s\) = salary, and \(t\) = effort (time)
Marginal disutility for effort increases with effort \(V(t) \ge 0, V'(t)>0, V''(t) >0\)
Constant marginal cost of production and distribution \(c\)
Known utility function and sales-effort response function (both principal and agent)
dollar sales \(x \sim Gamma, Binom\)
Expected profit for the firm
\[ \pi = \int[(1-c)x - s(x)]f(x|t)dx \]
Objective of the firm is to
\[ \underset{s(x)}{\operatorname{max}} \int[(1-c)x - s(x)]f(x|t)dx \]
subject to (agent’s best alternative e.g., other job offer - \(m\) )
\[ \int [U(s(x))]f(x|t) dx - V(t) \ge m \]
and the agent wants to maximize the the utility
\[ \underset{t}{\operatorname{max}} \int [U(s(x))]f(x|t)dx - V(t) \]
21.23.2 Lal and Staelin ( 1986 )
21.23.3 raju and srinivasan ( 1996 ).
Compare quota-based compensation with ( Basu et al. 1985 ) curvilinear compensation, the basic quota plan is simpler, and only in specical cases (about 1% in simulation) that differs from ( Basu et al. 1985 ) . And it’s easier to adapt to changes in moving salesperson and changing territory, unlike ( Basu et al. 1985 ) ’s plan where the whole commission rate structure needs to be changed.
Heterogeneity stems from:
Salesperson: disutility effort level, risk level, effectiveness, alternative opportunity
Territory: Sales potential an volatility
Adjusting the quota (per territory) can accommodate the heterogeneity
Quota-based < BLSS (in terms of profits)
- quota-based from curve (between total compensation and sales) (i.e., shape-induced nonoptimality)
- common salary and commission rate across salesforce (i.e., heterogeneity-induced nonoptimality)
To assess the shape-induced nonoptimality following
21.23.4 Joseph and Thevaranjan ( 1998 )
21.23.5 simester and zhang ( 2010 ).
- Tradeoff: Motivating manager effort and info sharing.
21.24 Meta-analyses of Econometric Marketing Models
21.25 dynamic advertising effects and spending models, 21.26 marketing mix optimization models.
Check this post for implementation in Python
21.27 New Product Diffusion Models
21.28 two-sided platform marketing models.
Example of Marketing Mix Model in practice: link
The Analytical Model and Research Methods
Cite this chapter.

- Norio Kambayashi
18 Accesses
The preceding chapter has shown how the concepts of IT use and national culture have been used in an organisational context in previous studies. It has illuminated to what degree previous studies have clarified these concepts and what kinds of drawbacks have been involved in them. Based on this review, this chapter provides explanations for the analytical framework and the research methods used in our study. I will begin by investigating what kinds of research approach are available in the discipline of IT/IS and which is appropriate for the purpose of this study. My analysis will make clear that the survey approach is well-suited for the topic being pursued. I will discuss how I approach IT use in an organisational setting and the analytical levels of IT use which are to be examined, and in the following section focus on how to operationalise national culture in the study including a review and discussion of some previous studies on conceptualisation and operationalisation of national culture. Then, specifying patterns of IT use which are sensitive to cultural influences, I develop a model of cultural influences on organisational IT use. The whole analytical framework used for the study is presented, and explanations of methodological details follow. Some preliminary work for the field study and the pilot study done before the survey are also given and the chosen techniques of data collection and the structure of the collected data are illustrated in the final section.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
- Durable hardcover edition
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Unable to display preview. Download preview PDF.
You can also search for this author in PubMed Google Scholar
Copyright information
© 2003 Norio Kambayashi
About this chapter
Kambayashi, N. (2003). The Analytical Model and Research Methods. In: Cultural Influences on IT Use. Palgrave Macmillan, London. https://doi.org/10.1057/9780230511118_3
Download citation
DOI : https://doi.org/10.1057/9780230511118_3
Publisher Name : Palgrave Macmillan, London
Print ISBN : 978-1-349-50772-6
Online ISBN : 978-0-230-51111-8
eBook Packages : Palgrave Business & Management Collection Business and Management (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research

You are here
Standard methodology for analytical models.
In this document, the Standard Methodology for Analytical Models (SMAM) is described. A short overview of the SMAM phases can be found in Table 1. The most frequent used methodology is the Cross Industrial Standard Processes for Data Mining (CRISP-DM)[1], which has several shortcomings that translate into frequent friction points with the business when practitioners start building analytical models.

The document will start with a discussion of the phases of the CRISP-DM and highlight its shortcomings. Subsequently, the phases of the SMAM will be described. A set of tables is provided that can serve as guidance to define the creation of a new analytical model.
Introduction
In the recent decades, the creation and use of analytical models has become common good in every industry. Analytical models have greatly evolved both in the depths of the mathematical techniques as well as the wide-spread application of the results. The methodology to create analytical models, however, is not well described, as can be seen by the fact that the job of the analytic practitioners (currently called data scientists; older names are statistician, data analyst and data miner) involve a lot of tacit knowledge, practical knowledge not easily reducible to articulated rules[2]. This informality can be seen in many areas of analytical modeling, ranging from the project methodology, the creation of the modeling & validation data, the analytical model-building approaches to model reporting. The focus of this document is project methodology.
The best known project methodology for analytical processes is Cross Industrial Standard Processes for Data Mining (CRISP-DM)[1]. This methodology describes six phases that show an iterative approach to the development of analytical models. Although it describes the general approach to analytical model creation (Business understanding, Data understanding, Data preparation, Modeling, Evaluation, Deployment), it lacks nuances that describe how analytical model building in a business context actually flows as an end-to-end process. The effects of the shortcomings of CRISP-DM translate into multiple friction points with the business when practitioners start building analytical models.
Shortcomings of the current methodology
Examples of these friction points will be well recognized by data scientists. Not limited to the set of examples given, friction points for the various phases include:
CRISP-DM: Business Understanding
Phase definition : this initial phase focuses on understanding the project objectives and requirements from a business perspective, and then converting this knowledge into a data mining problem definition, and a preliminary plan designed to achieve the objectives[3].
Issues : this view is often understood as only the data scientist who needs to understand the business issues while the business knowing exactly what they want. In reality, often the business intends to ‘make smarter decisions by using data’, but they lack the understanding of what analytical models are, how they can or should be used and what realistic expectations are around model effectiveness. As such, the business itself needs to transform in order to work with analytical models.
Another issue with the Business Understanding phase is that project objectives and project requirements are usually originating from different parts of the organization. The objectives typically come from a higher management level than the requirements and ignoring this fact, not seldom leads to the situation where after the model has been developed, the end-users of the analytical model are required to post-rationalize the model, which leads to a lot of dissatisfaction.
CRISP-DM: Modeling
Phase definition : in this phase, various modeling techniques are selected and applied, and their parameters are calibrated to optimal values3.
Issues : although this definition gives room for trying out different techniques, it very much underestimates the amount real experimentation that is needed to get at viable results, especially if a use-case if not a common, well-known one. True experimentation may require changing to an entire different format of the data, or even a different interpretation or adjustment of the business question.
CRISP-DM: Evaluation
Phase definition : at this stage in the project, you have built a model that appears to have high quality, from a data analysis perspective. Before proceeding to final deployment of the model, it is important to more thoroughly evaluate the model, and review the steps executed to construct the model, to be certain it properly achieves the business objectives[3].
Issue : thorough evaluation indeed is needed, yet the CRISP-DM methodology does not prescribe how to do this. As a result, evaluation is done on historic data, in the worst case, on a hold-out partition of the training data, in a slightly better case, on an out-of-time validation sample. As a model typically impacts an important part of the business, it is a good practice to device a proper experiment, whereby the model is tested in a limited fashion on new data. A proper experiment will also include an ROI calculation, which can be used to decide if the model is good enough to be implemented. Model evaluations often result in wry discussions with the business, who invariably expects analytical models to be accurate for 90% and up, irrespective of, and not bothered by the specific measure of accuracy. A limited experimental setting resulting in an ROI computation can help change this discussion to a more productive one.
Commonly, another issue with the evaluation phase is the lack of verbosity of the analytical model for the parties involved. One of the 9 laws of data mining states that ‘Data mining amplifies perception in the business domain’[4]. This very fact seems to urge that (lasting) visualization and dashboards reporting need to be integral part of the model building output. This concerns both what the model does (analytical reporting) as well as how the model impacts the business (operational reporting).
CRISP-DM: Deployment
Phase definition : depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data scoring[3].
Issues : besides that fact that the deployment of the model needs to be discussed very much at the identification of the use-case (considering the availability and timing of scoring data and the costs of integration), the view of a single deployment phase is too simplistic. The deployment itself involves multiple phases, and needs to be defined using its own hand-over process, as this is the moment where the data scientists hands-over the resulting model to IT or an operational team who will ensure continuous execution of the model. In addition, the life cycle of the model needs to be taken into account, both from a model effectiveness perspective as well as from a model evolution perspective.
In the previous paragraphs, the short comings of the CRISP-DM were discussed, whereby the issues raised are the reversed view of the improvements made in the Standard Methodology for Analytical Models (SMAM). The phases of the SMAM are as follows:
Use-case identification
The use-case identification phase describes the brainstorming/discovery process of looking at the different areas where models may be applicable. It involves education of the business parties involved on what analytical modeling is, what realistic expectations are from the various approaches and how models can be leveraged in the business. Discussions on the use-case identification involve topics around data availability, model integration complexity, analytical model complexity and model impact on the business. From a list of identified use-cases in an area, the one with the best ranking on above mentioned criteria should be considered for implementation. Note that, businesses often are not familiar with this very first data/fact based funneling step, and as a result, they will have to let go of their religiously held initial –and much to complex- analytic modeling idea. Parties involved in this phase are (higher) management, to ensure the right goal setting, IT for data availability, the involved department for model relevance checking and the data scientists to infuse the analytical knowledge and creative analytical idea provisioning. The result of this phase is a choses use-case, and potentially a roadmap with the other considered initiatives on a timeline.
Model requirements gathering
The use-case requirements gathering phase describes the process where for the chosen use-case, the set of conditions are explored that need to hold for the model to be viable in the business process. A not exhaustive list of topics of discussion are conditions for the cases/customers/entities considered for scoring, side-conditions that need to hold, consistency checks that need to hold, handling of unexpected predictions, or unexpected input data, requirements about the availability of the scores, the timing of scores (and the data), the frequency of refresh of the scores; initial ideas around model reporting can be explored and finally, ways that the end-users would like to consume the results of the analytical models. Parties involved in this phase are people from the involved department(s), the end-users and the data scientists. The result of this phase is a requirements document.
Data preparation
In the data preparation phase, the discussions revolve around data access, data location, data understanding, data validation, and creation of the modeling data. It is needed to create an understanding of the operational data required for scoring, both from an availability (cost) and timing perspective. This is a phase where IT/data administrators/DBA’s closely work together with the data scientist to help prepare the data in a format consumable by the data scientist. The process is agile; the data scientist tries out various approaches on smaller sets and then may ask IT to perform the required transformation in large. As with the CRISP-DM, the previous phase, this phase and the next happen in that order, but often jump back and forth. The involved parties are IT/data administrators/DBA/data modelers and data scientists. The end of this phase is not so clearly defined. One could argue that the results of this phase should be the data scientist being convinced that with the data available, a model is viable, as well as the scoring of the model in the operational environment.
Modeling experiments
In the modeling experiment phase, the core data scientist is at his/her element. This is where they can play with the data; crack the nut; trying to come up with the solution that is both cool, elegant and working. Results are not immediate; progress is obtained by evolution and by patiently collecting insights to put them together in an ever evolving model. At times, the solution at hand may not look viable anymore, and an entire different angle needs to be explored, seemingly starting from scratch. It is important to set the right expectations for this phase. There is no free lunch for the data scientist, although the business always seems to think so. The term data science[5] does honor to what is being done here: it is scientific research, with all its struggles, its Eureka’s, and its need for meticulous experimentation. The topic of the research: data, and hence the fitting term: data science. The data scientist may need to connect to end-user to validate initial results, or to have discussion to get ideas which can be translated into testable hypotheses/model features. The result of this phase is an analytical model that is evaluated in the best possible way with the (historic) data available as well as a reporting of these facts.
Insight creation
Dashboards and visualization are critically important for the acceptance of the model by the business. In analytical aspiring companies, analytical models often are reported on by a very technical model report, at the birth of the model in a non-repeatable format. In more mature analytical practice, the modeling data is used for insight creation is a repeatable way. Topics of discussion in this phase are analytic reporting and operational reporting. Analytical reporting refers to any reporting on data where the outcome (of the analytical model) has already been observed. This data can then be used to understand the performance of the model and the evolution of performance over time. Creating structural analytic performance reports also pave the way for structural proper testing using control groups. Operational reporting refers to any reporting on the data where the outcome has not yet been observed. This data can be used to understand what the model predicts for the future in an aggregated sense and is used for monitoring purposes. For both types of reporting, insights are typically created by looking at behavior of subgroups as qualified by the model. By creating a structural reporting facility for the insights, it allows deeper insight in changing patterns that can be used by business users, as a ‘free’ addition to the repeated scoring of the analytical model. The involved parties are the end-users, the involved business department, potentially a reporting department and the data scientists. The result of this phase is a set of visualizations and dashboards that provide a clear view on the model effectiveness and provide business usable insights.
Proof of Value: ROI
Analytical models typically start as an experiment where, at the start of the project, the results cannot be guaranteed. Results depend on the quality of the data and the (unobservable) knowledge that the data contains about the phenomenon to be modeled, as well the quality of the data scientist, the time spent on the creation of the solution and the current state of the art of analytical models. As stated earlier, the business is not educated to think about the quality of analytical models in a technical way, nor should they necessarily get there. However, as the model impacts many business targets, the involved parties in the business need to be sure that they can trust the model (very concrete: their bonuses depend on their business performance, and hence the performance of the analytical model may determine their bonus). An accuracy of 90% seems to be a good target for an analytical model from business perspective, irrespective of the understanding of the measure of accuracy involved. Yet, the criteria influencing the quality of an analytical model are discussed above and cannot be commanded by the business. To jump out of this back-and-forth discussion, a proper experiment needs to be set up: in a limited fashion, the analytical model is applied to new data and the outcomes are measured in such a way that the result can be made financial. If the ROI is positive enough, the business will be convinced that they can trust the model; the model is proven to generalize well once more, and a decision can be made if the model should be deployed or not. Topics of discussion are around the setup of the experiment, control groups, measuring the model effectiveness, computation of the ROI and the success criteria. The people involved are the end-users, potentially the finance department, the IT department in order to provide the new data for the experiment and the data scientists. The result of this phase is a report on the experimental setup, the criteria around the measurements and the outcome.
Operationalization
The operationalization phase is not applicable to all models, although, the models that are most valuable are not one-time executions, but are embedded, repeatable scoring generators that the business can act upon. The operationalization is a phase where the data scientist closely works with the IT department. The model development took place in a relatively unstructured environment that gave the possibility to play with data and experiment with modeling approaches. Embedding an analytical model in the business means it migrates from this loosely defined environment to a location of rigor and structure. The discussions that the data scientist and the IT operator need to have, revolve around a hand-over process of the model. In addition, the IT operator needs to understand the data requirement of the model and needs to prepare the operational environment for this. The hand-over of a model to an operational team needs to come with an audit structure. If integration in end-user systems is required, programmers are involved, guided by the data scientist on the workings of the analytical model. Moreover, for the integration itself, an IT change process such as Agile[6] may be defined. The result of the initial part of this phase is a hand-over document where all parties involved agree on the coming process. The final result of this phase is a functional analytical model, that is, repeatable scores of the model are available to the business process in order help makes better decisions.
Model lifecycle
An analytical model in production will not be fit forever. Depending on how fast the business changes, the model performance degrades over time. The insight creation phase took care of the monitoring of this performance; the model life cycle phase defines what needs to happen. Generally, two types of model changes can happen: refresh and upgrade. In a model refresh, the model is trained with more recent data, leaving the model structurally untouched. The model upgrade is typically initiated by the availability of new data sources and the request from the business to improve model performance by the inclusion of the new sources. The involved parties are the end-users, the operational team that handles the model execution, the IT/data administrators/DBA for the new data and the data scientist. The result of this phase is, during the construction of the phase, a document describing the governance and agreement on the change processes around the model refresh/upgrades. On execution, the result is a model that is once more effective for the duration it lasts.
- Shearer C., The CRISP-DM model: the new blueprint for data mining , J Data Warehousing (2000); 5:13—22.
- Doing Data Science: Straight Talk from the Frontline, Rachel Schutt, Cathy O'Neil. O'Reilly Media, Inc. (2013), p359.
- http://en.wikipedia.org/wiki/Cross_Industry_Standard_Process_for_Data_Mining
- http://khabaza.codimension.net/index_files/9laws.htm
- http://en.wikipedia.org/wiki/Data_science
- http://en.wikipedia.org/wiki/Agile_software_development
Summary of phases in tables
Below follows an overview in table format of the different phases.
A non-picture version of those tables is available at
http://olavlaudy.com/index.php?title=Standard_methodology_for_analytical_models

Qualitative Data Analysis Methods 101:
The “big 6” methods + examples.
By: Kerryn Warren (PhD) | Reviewed By: Eunice Rautenbach (D.Tech) | May 2020 (Updated April 2023)
Qualitative data analysis methods. Wow, that’s a mouthful.
If you’re new to the world of research, qualitative data analysis can look rather intimidating. So much bulky terminology and so many abstract, fluffy concepts. It certainly can be a minefield!
Don’t worry – in this post, we’ll unpack the most popular analysis methods , one at a time, so that you can approach your analysis with confidence and competence – whether that’s for a dissertation, thesis or really any kind of research project.

What (exactly) is qualitative data analysis?
To understand qualitative data analysis, we need to first understand qualitative data – so let’s step back and ask the question, “what exactly is qualitative data?”.
Qualitative data refers to pretty much any data that’s “not numbers” . In other words, it’s not the stuff you measure using a fixed scale or complex equipment, nor do you analyse it using complex statistics or mathematics.
So, if it’s not numbers, what is it?
Words, you guessed? Well… sometimes , yes. Qualitative data can, and often does, take the form of interview transcripts, documents and open-ended survey responses – but it can also involve the interpretation of images and videos. In other words, qualitative isn’t just limited to text-based data.
So, how’s that different from quantitative data, you ask?
Simply put, qualitative research focuses on words, descriptions, concepts or ideas – while quantitative research focuses on numbers and statistics . Qualitative research investigates the “softer side” of things to explore and describe , while quantitative research focuses on the “hard numbers”, to measure differences between variables and the relationships between them. If you’re keen to learn more about the differences between qual and quant, we’ve got a detailed post over here .

So, qualitative analysis is easier than quantitative, right?
Not quite. In many ways, qualitative data can be challenging and time-consuming to analyse and interpret. At the end of your data collection phase (which itself takes a lot of time), you’ll likely have many pages of text-based data or hours upon hours of audio to work through. You might also have subtle nuances of interactions or discussions that have danced around in your mind, or that you scribbled down in messy field notes. All of this needs to work its way into your analysis.
Making sense of all of this is no small task and you shouldn’t underestimate it. Long story short – qualitative analysis can be a lot of work! Of course, quantitative analysis is no piece of cake either, but it’s important to recognise that qualitative analysis still requires a significant investment in terms of time and effort.
Need a helping hand?
In this post, we’ll explore qualitative data analysis by looking at some of the most common analysis methods we encounter. We’re not going to cover every possible qualitative method and we’re not going to go into heavy detail – we’re just going to give you the big picture. That said, we will of course includes links to loads of extra resources so that you can learn more about whichever analysis method interests you.
Without further delay, let’s get into it.
The “Big 6” Qualitative Analysis Methods
There are many different types of qualitative data analysis, all of which serve different purposes and have unique strengths and weaknesses . We’ll start by outlining the analysis methods and then we’ll dive into the details for each.
The 6 most popular methods (or at least the ones we see at Grad Coach) are:
- Content analysis
- Narrative analysis
- Discourse analysis
- Thematic analysis
- Grounded theory (GT)
- Interpretive phenomenological analysis (IPA)
Let’s take a look at each of them…
QDA Method #1: Qualitative Content Analysis
Content analysis is possibly the most common and straightforward QDA method. At the simplest level, content analysis is used to evaluate patterns within a piece of content (for example, words, phrases or images) or across multiple pieces of content or sources of communication. For example, a collection of newspaper articles or political speeches.
With content analysis, you could, for instance, identify the frequency with which an idea is shared or spoken about – like the number of times a Kardashian is mentioned on Twitter. Or you could identify patterns of deeper underlying interpretations – for instance, by identifying phrases or words in tourist pamphlets that highlight India as an ancient country.
Because content analysis can be used in such a wide variety of ways, it’s important to go into your analysis with a very specific question and goal, or you’ll get lost in the fog. With content analysis, you’ll group large amounts of text into codes , summarise these into categories, and possibly even tabulate the data to calculate the frequency of certain concepts or variables. Because of this, content analysis provides a small splash of quantitative thinking within a qualitative method.
Naturally, while content analysis is widely useful, it’s not without its drawbacks . One of the main issues with content analysis is that it can be very time-consuming , as it requires lots of reading and re-reading of the texts. Also, because of its multidimensional focus on both qualitative and quantitative aspects, it is sometimes accused of losing important nuances in communication.
Content analysis also tends to concentrate on a very specific timeline and doesn’t take into account what happened before or after that timeline. This isn’t necessarily a bad thing though – just something to be aware of. So, keep these factors in mind if you’re considering content analysis. Every analysis method has its limitations , so don’t be put off by these – just be aware of them ! If you’re interested in learning more about content analysis, the video below provides a good starting point.
QDA Method #2: Narrative Analysis
As the name suggests, narrative analysis is all about listening to people telling stories and analysing what that means . Since stories serve a functional purpose of helping us make sense of the world, we can gain insights into the ways that people deal with and make sense of reality by analysing their stories and the ways they’re told.
You could, for example, use narrative analysis to explore whether how something is being said is important. For instance, the narrative of a prisoner trying to justify their crime could provide insight into their view of the world and the justice system. Similarly, analysing the ways entrepreneurs talk about the struggles in their careers or cancer patients telling stories of hope could provide powerful insights into their mindsets and perspectives . Simply put, narrative analysis is about paying attention to the stories that people tell – and more importantly, the way they tell them.
Of course, the narrative approach has its weaknesses , too. Sample sizes are generally quite small due to the time-consuming process of capturing narratives. Because of this, along with the multitude of social and lifestyle factors which can influence a subject, narrative analysis can be quite difficult to reproduce in subsequent research. This means that it’s difficult to test the findings of some of this research.
Similarly, researcher bias can have a strong influence on the results here, so you need to be particularly careful about the potential biases you can bring into your analysis when using this method. Nevertheless, narrative analysis is still a very useful qualitative analysis method – just keep these limitations in mind and be careful not to draw broad conclusions . If you’re keen to learn more about narrative analysis, the video below provides a great introduction to this qualitative analysis method.

QDA Method #3: Discourse Analysis
Discourse is simply a fancy word for written or spoken language or debate . So, discourse analysis is all about analysing language within its social context. In other words, analysing language – such as a conversation, a speech, etc – within the culture and society it takes place. For example, you could analyse how a janitor speaks to a CEO, or how politicians speak about terrorism.
To truly understand these conversations or speeches, the culture and history of those involved in the communication are important factors to consider. For example, a janitor might speak more casually with a CEO in a company that emphasises equality among workers. Similarly, a politician might speak more about terrorism if there was a recent terrorist incident in the country.
So, as you can see, by using discourse analysis, you can identify how culture , history or power dynamics (to name a few) have an effect on the way concepts are spoken about. So, if your research aims and objectives involve understanding culture or power dynamics, discourse analysis can be a powerful method.
Because there are many social influences in terms of how we speak to each other, the potential use of discourse analysis is vast . Of course, this also means it’s important to have a very specific research question (or questions) in mind when analysing your data and looking for patterns and themes, or you might land up going down a winding rabbit hole.
Discourse analysis can also be very time-consuming as you need to sample the data to the point of saturation – in other words, until no new information and insights emerge. But this is, of course, part of what makes discourse analysis such a powerful technique. So, keep these factors in mind when considering this QDA method. Again, if you’re keen to learn more, the video below presents a good starting point.
QDA Method #4: Thematic Analysis
Thematic analysis looks at patterns of meaning in a data set – for example, a set of interviews or focus group transcripts. But what exactly does that… mean? Well, a thematic analysis takes bodies of data (which are often quite large) and groups them according to similarities – in other words, themes . These themes help us make sense of the content and derive meaning from it.
Let’s take a look at an example.
With thematic analysis, you could analyse 100 online reviews of a popular sushi restaurant to find out what patrons think about the place. By reviewing the data, you would then identify the themes that crop up repeatedly within the data – for example, “fresh ingredients” or “friendly wait staff”.
So, as you can see, thematic analysis can be pretty useful for finding out about people’s experiences , views, and opinions . Therefore, if your research aims and objectives involve understanding people’s experience or view of something, thematic analysis can be a great choice.
Since thematic analysis is a bit of an exploratory process, it’s not unusual for your research questions to develop , or even change as you progress through the analysis. While this is somewhat natural in exploratory research, it can also be seen as a disadvantage as it means that data needs to be re-reviewed each time a research question is adjusted. In other words, thematic analysis can be quite time-consuming – but for a good reason. So, keep this in mind if you choose to use thematic analysis for your project and budget extra time for unexpected adjustments.
")
QDA Method #5: Grounded theory (GT)
Grounded theory is a powerful qualitative analysis method where the intention is to create a new theory (or theories) using the data at hand, through a series of “ tests ” and “ revisions ”. Strictly speaking, GT is more a research design type than an analysis method, but we’ve included it here as it’s often referred to as a method.
What’s most important with grounded theory is that you go into the analysis with an open mind and let the data speak for itself – rather than dragging existing hypotheses or theories into your analysis. In other words, your analysis must develop from the ground up (hence the name).
Let’s look at an example of GT in action.
Assume you’re interested in developing a theory about what factors influence students to watch a YouTube video about qualitative analysis. Using Grounded theory , you’d start with this general overarching question about the given population (i.e., graduate students). First, you’d approach a small sample – for example, five graduate students in a department at a university. Ideally, this sample would be reasonably representative of the broader population. You’d interview these students to identify what factors lead them to watch the video.
After analysing the interview data, a general pattern could emerge. For example, you might notice that graduate students are more likely to read a post about qualitative methods if they are just starting on their dissertation journey, or if they have an upcoming test about research methods.
From here, you’ll look for another small sample – for example, five more graduate students in a different department – and see whether this pattern holds true for them. If not, you’ll look for commonalities and adapt your theory accordingly. As this process continues, the theory would develop . As we mentioned earlier, what’s important with grounded theory is that the theory develops from the data – not from some preconceived idea.
So, what are the drawbacks of grounded theory? Well, some argue that there’s a tricky circularity to grounded theory. For it to work, in principle, you should know as little as possible regarding the research question and population, so that you reduce the bias in your interpretation. However, in many circumstances, it’s also thought to be unwise to approach a research question without knowledge of the current literature . In other words, it’s a bit of a “chicken or the egg” situation.
Regardless, grounded theory remains a popular (and powerful) option. Naturally, it’s a very useful method when you’re researching a topic that is completely new or has very little existing research about it, as it allows you to start from scratch and work your way from the ground up .
")
QDA Method #6: Interpretive Phenomenological Analysis (IPA)
Interpretive. Phenomenological. Analysis. IPA . Try saying that three times fast…
Let’s just stick with IPA, okay?
IPA is designed to help you understand the personal experiences of a subject (for example, a person or group of people) concerning a major life event, an experience or a situation . This event or experience is the “phenomenon” that makes up the “P” in IPA. Such phenomena may range from relatively common events – such as motherhood, or being involved in a car accident – to those which are extremely rare – for example, someone’s personal experience in a refugee camp. So, IPA is a great choice if your research involves analysing people’s personal experiences of something that happened to them.
It’s important to remember that IPA is subject – centred . In other words, it’s focused on the experiencer . This means that, while you’ll likely use a coding system to identify commonalities, it’s important not to lose the depth of experience or meaning by trying to reduce everything to codes. Also, keep in mind that since your sample size will generally be very small with IPA, you often won’t be able to draw broad conclusions about the generalisability of your findings. But that’s okay as long as it aligns with your research aims and objectives.
Another thing to be aware of with IPA is personal bias . While researcher bias can creep into all forms of research, self-awareness is critically important with IPA, as it can have a major impact on the results. For example, a researcher who was a victim of a crime himself could insert his own feelings of frustration and anger into the way he interprets the experience of someone who was kidnapped. So, if you’re going to undertake IPA, you need to be very self-aware or you could muddy the analysis.

How to choose the right analysis method
In light of all of the qualitative analysis methods we’ve covered so far, you’re probably asking yourself the question, “ How do I choose the right one? ”
Much like all the other methodological decisions you’ll need to make, selecting the right qualitative analysis method largely depends on your research aims, objectives and questions . In other words, the best tool for the job depends on what you’re trying to build. For example:
- Perhaps your research aims to analyse the use of words and what they reveal about the intention of the storyteller and the cultural context of the time.
- Perhaps your research aims to develop an understanding of the unique personal experiences of people that have experienced a certain event, or
- Perhaps your research aims to develop insight regarding the influence of a certain culture on its members.
As you can probably see, each of these research aims are distinctly different , and therefore different analysis methods would be suitable for each one. For example, narrative analysis would likely be a good option for the first aim, while grounded theory wouldn’t be as relevant.
It’s also important to remember that each method has its own set of strengths, weaknesses and general limitations. No single analysis method is perfect . So, depending on the nature of your research, it may make sense to adopt more than one method (this is called triangulation ). Keep in mind though that this will of course be quite time-consuming.
As we’ve seen, all of the qualitative analysis methods we’ve discussed make use of coding and theme-generating techniques, but the intent and approach of each analysis method differ quite substantially. So, it’s very important to come into your research with a clear intention before you decide which analysis method (or methods) to use.
Start by reviewing your research aims , objectives and research questions to assess what exactly you’re trying to find out – then select a qualitative analysis method that fits. Never pick a method just because you like it or have experience using it – your analysis method (or methods) must align with your broader research aims and objectives.

Let’s recap on QDA methods…
In this post, we looked at six popular qualitative data analysis methods:
- First, we looked at content analysis , a straightforward method that blends a little bit of quant into a primarily qualitative analysis.
- Then we looked at narrative analysis , which is about analysing how stories are told.
- Next up was discourse analysis – which is about analysing conversations and interactions.
- Then we moved on to thematic analysis – which is about identifying themes and patterns.
- From there, we went south with grounded theory – which is about starting from scratch with a specific question and using the data alone to build a theory in response to that question.
- And finally, we looked at IPA – which is about understanding people’s unique experiences of a phenomenon.
Of course, these aren’t the only options when it comes to qualitative data analysis, but they’re a great starting point if you’re dipping your toes into qualitative research for the first time.
If you’re still feeling a bit confused, consider our private coaching service , where we hold your hand through the research process to help you develop your best work.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
87 Comments

This has been very helpful. Thank you.

Thank you madam,

Thank you so much for this information

I wonder it so clear for understand and good for me. can I ask additional query?

Very insightful and useful

Good work done with clear explanations. Thank you.

Thanks so much for the write-up, it’s really good.

Thanks madam . It is very important .

thank you very good

Great presentation

This has been very well explained in simple language . It is useful even for a new researcher.

Great to hear that. Good luck with your qualitative data analysis, Pramod!

This is very useful information. And it was very a clear language structured presentation. Thanks a lot.

Thank you so much.

very informative sequential presentation

Precise explanation of method.

Hi, may we use 2 data analysis methods in our qualitative research?
Thanks for your comment. Most commonly, one would use one type of analysis method, but it depends on your research aims and objectives.

You explained it in very simple language, everyone can understand it. Thanks so much.

Thank you very much, this is very helpful. It has been explained in a very simple manner that even a layman understands

Thank nicely explained can I ask is Qualitative content analysis the same as thematic analysis?
Thanks for your comment. No, QCA and thematic are two different types of analysis. This article might help clarify – https://onlinelibrary.wiley.com/doi/10.1111/nhs.12048

This is my first time to come across a well explained data analysis. so helpful.

I have thoroughly enjoyed your explanation of the six qualitative analysis methods. This is very helpful. Thank you!

Thank you very much, this is well explained and useful

i need a citation of your book.

Thanks a lot , remarkable indeed, enlighting to the best

Hi Derek, What other theories/methods would you recommend when the data is a whole speech?

Keep writing useful artikel.

It is important concept about QDA and also the way to express is easily understandable, so thanks for all.

Thank you, this is well explained and very useful.

Very helpful .Thanks.

Hi there! Very well explained. Simple but very useful style of writing. Please provide the citation of the text. warm regards

The session was very helpful and insightful. Thank you
This was very helpful and insightful. Easy to read and understand

As a professional academic writer, this has been so informative and educative. Keep up the good work Grad Coach you are unmatched with quality content for sure.
Keep up the good work Grad Coach you are unmatched with quality content for sure.

Its Great and help me the most. A Million Thanks you Dr.

It is a very nice work

Very insightful. Please, which of this approach could be used for a research that one is trying to elicit students’ misconceptions in a particular concept ?

This is Amazing and well explained, thanks

great overview

What do we call a research data analysis method that one use to advise or determining the best accounting tool or techniques that should be adopted in a company.

Informative video, explained in a clear and simple way. Kudos

Waoo! I have chosen method wrong for my data analysis. But I can revise my work according to this guide. Thank you so much for this helpful lecture.

This has been very helpful. It gave me a good view of my research objectives and how to choose the best method. Thematic analysis it is.

Very helpful indeed. Thanku so much for the insight.

This was incredibly helpful.

Very helpful.

very educative

Nicely written especially for novice academic researchers like me! Thank you.

choosing a right method for a paper is always a hard job for a student, this is a useful information, but it would be more useful personally for me, if the author provide me with a little bit more information about the data analysis techniques in type of explanatory research. Can we use qualitative content analysis technique for explanatory research ? or what is the suitable data analysis method for explanatory research in social studies?

that was very helpful for me. because these details are so important to my research. thank you very much

I learnt a lot. Thank you

Relevant and Informative, thanks !

Well-planned and organized, thanks much! 🙂

I have reviewed qualitative data analysis in a simplest way possible. The content will highly be useful for developing my book on qualitative data analysis methods. Cheers!

Clear explanation on qualitative and how about Case study

This was helpful. Thank you

This was really of great assistance, it was just the right information needed. Explanation very clear and follow.
Wow, Thanks for making my life easy

This was helpful thanks .

Very helpful…. clear and written in an easily understandable manner. Thank you.

This was so helpful as it was easy to understand. I’m a new to research thank you so much.

so educative…. but Ijust want to know which method is coding of the qualitative or tallying done?

Thank you for the great content, I have learnt a lot. So helpful

precise and clear presentation with simple language and thank you for that.

very informative content, thank you.

You guys are amazing on YouTube on this platform. Your teachings are great, educative, and informative. kudos!

Brilliant Delivery. You made a complex subject seem so easy. Well done.

Beautifully explained.
Thanks a lot

Is there a video the captures the practical process of coding using automated applications?
Thanks for the comment. We don’t recommend using automated applications for coding, as they are not sufficiently accurate in our experience.

content analysis can be qualitative research?

THANK YOU VERY MUCH.

Thank you very much for such a wonderful content

do you have any material on Data collection

What a powerful explanation of the QDA methods. Thank you.

Great explanation both written and Video. i have been using of it on a day to day working of my thesis project in accounting and finance. Thank you very much for your support.

very helpful, thank you so much

The tutorial is useful. I benefited a lot.

This is an eye opener for me and very informative, I have used some of your guidance notes on my Thesis, I wonder if you can assist with your 1. name of your book, year of publication, topic etc., this is for citing in my Bibliography,
I certainly hope to hear from you
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
A review of analytical models, approaches and decision support tools in project monitoring and control
- September 2014
- International Journal of Project Management 33(4)

- Rennes School of Business
Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- AUTOMAT CONSTR
- Yaning Zhang

- Jose M Gonzalez-Varona

- Nermeen Bahnas

- Gary D. Beckman
- Karl Androes

- J Model Manag

- Mehran Ziaeian

- Mohammad Ali Zare

- Lisa Ingall
- Int J Proj Manag

- Proj Manag J

- Stuart Spraggett

- Gerald L. Thompson
- DECIS SUPPORT SYST

- M.M. Kablan

- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
- - Google Chrome
Intended for healthcare professionals
- My email alerts
- BMA member login
- Username * Password * Forgot your log in details? Need to activate BMA Member Log In Log in via OpenAthens Log in via your institution
Search form
- Advanced search
- Search responses
- Search blogs
- Economic evaluation...
Economic evaluation using decision analytical modelling: design, conduct, analysis, and reporting
- Related content
- Peer review
- Stavros Petrou , professor of health economics 1 ,
- Alastair Gray , professor of health economics 2
- 1 Clinical Trials Unit, Warwick Medical School, University of Warwick, Coventry CV4 7AL, UK
- 2 Health Economics Research Centre, Department of Public Health, University of Oxford, Oxford, UK
- Correspondence to: S Petrou S.Petrou{at}warwick.ac.uk
- Accepted 8 February 2011
Evidence relating to healthcare decisions often comes from more than one study. Decision analytical modelling can be used as a basis for economic evaluations in these situations.
Economic evaluations are increasingly conducted alongside randomised controlled trials, providing researchers with individual patient data to estimate cost effectiveness. 1 However, randomised trials do not always provide a sufficient basis for economic evaluations used to inform regulatory and reimbursement decisions. For example, a single trial might not compare all the available options, provide evidence on all relevant inputs, or be conducted over a long enough time to capture differences in economic outcomes (or even measure those outcomes). 2 In addition, reliance on a single trial may mean ignoring evidence from other trials, meta-analyses, and observational studies. Under these circumstances, decision analytical modelling provides an alternative framework for economic evaluation.
Decision analytical modelling compares the expected costs and consequences of decision options by synthesising information from multiple sources and applying mathematical techniques, usually with computer software. The aim is to provide decision makers with the best available evidence to reach a decision—for example, should a new drug be adopted? Following on from our article on trial based economic evaluations, 1 we outline issues relating to the design, conduct, analysis, and reporting of economic evaluations using decision analytical modelling.
Glossary of terms
Cost effectiveness acceptability curve —Graphical depiction of the probability that a health intervention is cost effective across a range of willingness to pay thresholds held by decision makers for the health outcome of interest
Cost effectiveness plane —Graphical depiction of difference in effectiveness between the new treatment and the comparator against the difference in cost
Discounting —The practice of reducing future costs and health outcomes to present values
Health utilities —Preference based outcomes normally represented on a scale where 0 represents death and 1 represents perfect health
Incremental cost effectiveness ratio —A measure of cost effectiveness of a health intervention compared with an alternative, defined as the difference in costs divided by the difference in effects
Multiparameter evidence synthesis— A generalisation of meta-analysis in which multiple variables are estimated jointly
Quality adjusted life year (QALY)—Preference-based measure of health outcome that combines length of life and health related quality of life (utility scores) in a single metric
Time horizon —The start and end points (in time) over which the costs and consequences of a health intervention will be measured and valued
Value of information analysis —An approach for estimating the monetary value associated with collecting additional information within economic evaluation
Defining the question
The first stage in the development of any model is to specify the question or decision problem. It is important to define all relevant options available for evaluation, the recipient population, and the geographical location and setting in which the options are being delivered. 3 The requirements of the decision makers should have a crucial role in identifying the appropriate perspective of the analysis, the time horizon, the relevant outcome measures, and, more broadly, the scope or boundaries of the model. 4 If these factors are unclear, or different decision makers have conflicting requirements, the perspective and scope should be broad enough to allow the results to be disaggregated in different ways. 5
Decision trees
The simplest form of decision analytical modelling in economic evaluation is the decision tree. Alternative options are represented by a series of pathways or branches as in figure 1 ⇓ , which examines whether it is cost effective to screen for breast cancer every two years compared with not screening. The first point in the tree, the decision node (drawn as a square) represents this decision question. In this instance only two options are represented, but additional options could easily be added. The pathways that follow each option represent a series of logically ordered alternative events, denoted by branches emanating from chance nodes (circular symbols). The alternatives at each chance node must be mutually exclusive and their probabilities should sum exactly to one. The end points of each pathway are denoted by terminal nodes (triangular symbols) to which values or pay-offs, such as costs, life years, or quality adjusted life years (QALYs), are assigned. Once the probabilities and pay-offs have been entered, the decision tree is “averaged out” and “folded back” (or rolled back), allowing the expected values of each option to be calculated. 4
Fig 1 Decision tree for breast cancer screening options 4
- Download figure
- Open in new tab
- Download powerpoint
Decision trees are valued for their simplicity and transparency, and they can be an excellent way of clarifying the options of interest. However, they are limited by the lack of any explicit time variable, making it difficult to deal with time dependent elements of an economic evaluation. 6 Recursion or looping within the decision tree is also not allowed, so that trees representing chronic diseases with recurring events can be complex with numerous lengthy pathways.
Markov models
An alternative form of modelling is the Markov model. Unlike decision trees, which represent sequences of events as a large number of potentially complex pathways, Markov models permit a more straightforward and flexible sequencing of outcomes, including recurring outcomes, through time. Patients are assumed to reside in one of a finite number of health states at any point in time and make transitions between those health states over a series of discrete time intervals or cycles. 3 6 The probability of staying in a state or moving to another one in each cycle is determined by a set of defined transition probabilities. The definition and number of health states and the duration of the cycles will be governed by the decision problem: one study of treatment for gastro-oesophageal reflux disease used one month cycles to capture treatment switches and side effects, 7 whereas an analysis of cervical cancer screening used six monthly cycles to model lifetime outcomes. 8
Figure 2 ⇓ presents a state transition diagram and matrix of transition probabilities for a Markov model of a hypothetical breast cancer intervention. There are three health states: well, recurrence of breast cancer, and dead. In this example, the probability of moving from the well state at time t to the recurrence state at time t+1 is 0.3, while the probability of moving from well to dead is 0.1. At each cycle the sum of the transition probabilities out of a health state (the row probabilities) must equal 1. In order for the Markov process to end, some termination condition must be set. This could be a specified number of cycles, a proportion passing through or accumulating in a particular state, or the entire population reaching a state that cannot be left (in our example, dead); this is called an absorbing state.
Fig 2 Markov state diagram and transition probability matrix for hypothetical breast cancer intervention. The arrows represent possible transitions between the three health states (well, recurrence, and dead), loops indicate the possibility of remaining in a health state in successive cycles, and the dashed line indicates the possibility of backwards transition from recurrence of breast cancer to the well state after successful treatment. The cycle length is set at one year
An important limitation of Markov models is the assumption that the transition probabilities depend only on the current health state, independent of historical experience (the Markovian assumption). In our example, the probability of a person dying from breast cancer is independent of the number of past recurrences and also independent of how long the person spent in the well state before moving to the recurrent state. This limitation can be overcome by introducing temporary states that patients can only enter for one cycle or by a series of temporary states that must be visited in a fixed sequence. 4
The final stage is to assign values to each health state, typically costs and health utilities. 6 9 Most commonly, such models simulate the transition of a hypothetical cohort of individuals through the Markov model over time, allowing the analyst to estimate expected costs and outcomes. This simply involves, for each cycle, summing costs and outcomes across health states, weighted by the proportion of the cohort expected to be in each state, and then summing across cycles. 3 If the time horizon of the model is over one year, discounting is usually applied to generate the present values of expected costs and outcomes. 1
Alternative modelling approaches
Although Markov models alone or in combination with decision trees are the most common models used in economic evaluations, other approaches are available.
Patient level simulation (or microsimulation) models the progression of individuals rather than hypothetical cohorts. The models track the progression of potentially heterogeneous individuals with the accumulating history of each individual determining transitions, costs, and health outcomes. 3 10 Unlike Markov models, they can simulate the time to next event rather than requiring equal length cycles and can also simulate multiple events occurring in parallel. 10
Discrete event simulations describe the progress of individuals through healthcare processes or systems, affecting their characteristics and outcomes over unrestricted time periods. 10 Discrete event simulations are not restricted to the use of equal time periods or the Markovian assumption and, unlike patient level simulation models, also allow individuals to interact with each other 11 —for example, in a transplant programme where organs are scarce and transplant decisions and outcomes for any individual affect everyone else in the queue.
Dynamic models allow internal feedback loops and time delays that affect the behaviour of the entire health system or population being studied. They are particularly valuable in studies of infectious diseases, where analysts may need to account for the evolving effects of factors such as herd immunity on the likelihood of infection over time, and their results can differ substantially from those obtained from static models. 12
The choice of modelling approach will depend on various factors, including the decision maker’s requirements. 10 11 13
Identifying, synthesising, and transforming data inputs
The process of identifying and synthesising evidence to populate a decision analytical model should be consistent with the general principles of evidence based medicine. 3 14 These principles are broadly established for clinical evidence. 15 Less clear is the strategy that should be adopted to identify and synthesise evidence on other variables, such as costs and health utilities, other than it should be transparent and appropriate given the objectives of the model. 16 Indeed, many health economists recognise that the time and resource constraints imposed by many funders of health technology assessments will tend to preclude systematic reviews of the evidence for all variables. 17
If evidence is not available from randomised trials, it has to be drawn from other sources, such as epidemiological or observational studies, medical records, or, more controversially, expert opinion. And sometimes the evidence from randomised trials may not be appropriate for use in the model—for example, cost data drawn from a trial might reflect protocol driven resource use rather than usual practice 18 or might not be generalisable to the jurisdiction of interest. 5 These methodological considerations have increased interest in multiparameter evidence synthesis (box) 19 in decision analytical modelling. These techniques acknowledge the importance of trying to incorporate correlations between variables in models, which may have an important influence on the resulting estimates of cost effectiveness. 2 However, accurately assessing the correlation between different clinical events, or between events and costs or health utilities, may be difficult without patient level data from a single source. Another complication is that evidence may have to be transformed in complex ways to meet the requirements of the model—for example, interval probabilities reported in the literature may have to be transformed into instantaneous rates and then into transition probabilities corresponding to the cycle length used in a Markov model. 3 4 14
Quantifying and reporting cost effectiveness
Once data on all variables required by the model have been assembled, the model is run for each intervention being evaluated in order to estimate its expected costs and expected outcomes (or effects). The results are typically compared in terms of incremental cost effectiveness ratios and depicted on the cost effectiveness plane (box). 1
Handling variability, uncertainty, and heterogeneity
The results of a decision analytical model are subject to the influences of variability, uncertainty, and heterogeneity, and these must be handled appropriately if decision makers are to be confident about the estimates of cost effectiveness. 3 13
Variability reflects the randomness arising from the modelling process itself—that is, the fact that models typically use random numbers when determining whether an event with a given probability of occurring happens or not in any given cycle or model run, so that an identical patient will experience different outcomes each time they proceed through the model. This variability, sometimes referred to as Monte Carlo uncertainty, is not informative and needs to be eliminated by running the model repeatedly until a stable estimate of the central tendency has been obtained. 20 There is little evidence or agreement on how many model runs are needed to eliminate such variability, but it may be many thousands.
Parameter uncertainty reflects the uncertainty and imprecision surrounding the value of model variables such as transition probabilities, costs, and health utilities. Standard sensitivity analysis, in which each variable is varied separately and independently, does not give a complete picture of the effects of joint uncertainty and correlation between variables. 6 Probabilistic sensitivity analysis, in which all variables are varied simultaneously using probability distributions informed by estimates of the sample mean and sampling error from the best available evidence, is therefore the preferred way of assessing parameter uncertainty. 13 Probabilistic sensitivity analysis is usually executed by running the model several thousand times, each time varying the parameter values across the specified distributions and recording the outputs—for example, costs and effects—until a distribution has been built up and confidence intervals can be estimated. Probabilistic sensitivity analysis also allows the analyst to present cost effectiveness acceptability curves, which show the probability that each intervention is cost effective at an assumed maximum willingness to pay for health gains. 21 If a model has been derived from a single dataset, bootstrapping can be used to model uncertainty—that is, repeatedly re-estimating the model using random subsamples drawn with replacement from the full sample. 22
Structural or model uncertainty reflects the uncertainty surrounding the structure of the model and the assumptions underpinning it—for example, the way a disease pathway is modelled. Such model uncertainty is usually examined with a sensitivity analysis, re-running the model with alternative structural assumptions. 6 Alternatively, several research groups could model the same decision problem in different ways and then compare their results in an agreed way. This approach has been used extensively in fields such as climate change but less commonly in health economics. However, one example is provided by the Mount Hood Challenge, which invited eight diabetes modelling groups to independently predict clinical trial outcomes on the basis of changes in risk factors and then compare their predictions. 23 How the results from different models can be reconciled in the absence of a gold standard is unclear; however, Bojke and colleagues have recommended some form of model averaging, whereby each model’s results could be weighted by a measure of model adequacy. 24
Finally, heterogeneity should be clearly differentiated from variability because it reflects differences in outcomes or in cost effectiveness that can in principle be explained by variations between subgroups of patients, either in terms of baseline characteristics such as age, risk level, or disease severity or in terms of both baseline characteristics and relative treatment effects. As in the analysis of clinical trials, subgroups should be predefined and carefully justified in terms of their clinical and economic relevance. 25 A model can then be re-run for different subgroups of patients.
Alternatively, heterogeneity can be addressed by making model variables functions of other variables—for example, transition probabilities between events or health states might be transformed into functions of age or disease severity. As with subgroup analysis in clinical trials, care must be taken to avoid generating apparently large differences in cost effectiveness that are not based on genuine evidence of heterogeneity. For example, Mihaylova et al, recognising the absence of evidence of heterogeneity in treatment effect across subgroups in the Heart Protection Study, applied the same relative risk reduction to different subgroups defined in terms of absolute risk levels at baseline, resulting in large but reliable differences in cost effectiveness. 26 27
Model evaluation
Evaluation is an important, and often overlooked, step in the development of a decision analytical model. Well evaluated models are more likely to be believed by decision makers. Three steps in model validation of escalating difficulty are face validation, internal validation, and external validation:
Face or descriptive validation entails checking whether the assumptions and structure of a model are reliable, sensible, and can be explained intuitively. 14 This may also require experiments to assess whether setting some variables at null or extreme values generates predictable effects on model outputs.
Internal validation requires thorough internal testing of the model—for example by getting an independent researcher or using different software to construct a replicate of the model and assess whether the results are consistent. 14 28 Internal validation of a model derived from a single data source, for example a Markov model being used to simulate long term outcomes beyond the end of a clinical trial, may involve proving that the model’s predicted results also fit the observed data used in the estimation. 22 In these circumstances some analysts also favour splitting the initial data in two and using one set to “train” or estimate the model and the other to test or validate the model. Some analysts also calibrate the model, adjusting variables to ensure that the results accord with aggregate and observable outcomes, such as overall survival. 29 This approach has been criticised as an ad hoc search for values that makes it impossible to characterise the uncertainty in the model correctly. 30
External validation assesses whether the model’s predictions match the observed results in a population or over a time period that was not used to construct the model. This might entail assessing whether the model can accurately predict future events. For example, the Mount Hood Challenge compared the predictions of the diabetes models with each other and the reported trial outcomes. 23 External validation might also be appropriate for calibrated models.
Value of additional research
Decision analytical models are increasingly used as a framework for indicating the need for and value of additional research. We have established that the analyst will never be certain that the value placed on each variable is correct. As a result, there are distributions surrounding the outputs of decision analytical models that can be estimated using probabilistic sensitivity analysis and synthesised using cost effectiveness acceptability curves. 6 These techniques indicate the probability that the decision to adopt an intervention on grounds of cost effectiveness is correct. The techniques also allow a quantification of the cost of making an incorrect decision, which when combined with the probability of making an incorrect decision generates the expected cost of uncertainty. This has become synonymous with the expected value of perfect information (EVPI)—that is, the monetary value associated with eliminating the possibility of making an incorrect decision by eliminating parameter uncertainty in the model. 31 A population-wide EVPI can be estimated by multiplying the EVPI estimate produced by a decision analytical model by the number of decisions expected to be made on the basis of the additional information. 32 This can then be compared with the potential costs of further research to determine whether further studies are economically worthwhile. 33 34 The approach has been extended in the form of expected value of partial perfect information (EVPPI), which estimates the value of obtaining perfect information on a subset of parameters in the model, and the expected value of sample information (EVSI), which focuses on optimal study design issues such as the optimal sample size of further studies. 3
Conclusions
Further detail on the design, conduct, analysis, and reporting of economic evaluations using decision analytical modelling is available elsewhere. 4 6 This article and our accompanying article 1 show that there is considerable overlap between modelling based and trial based economic evaluations, not only in their objectives but, for example, in dealing with heterogeneity and presenting results, and in both cases we have argued the benefits of using individual patient data. These two broad approaches should be viewed as complements rather than as competing alternatives.
Summary points
Decision analytical modelling for economic evaluation uses mathematical techniques to determine the expected costs and consequences of alternative options
Methods of modelling include decision trees, Markov models, patient level simulation models, discrete event simulations, and system dynamic models
The process of identifying and synthesising evidence for a model should be transparent and appropriate to decision makers’ objectives
The results of decision analytical models are subject to the influences of variability, uncertainty, and heterogeneity, and these must be handled appropriately
Validation of model based economic evaluations strengthens the credibility of their results
Cite this as: BMJ 2011;342:d1766
Contributors: SP conceived the idea for this article. Both authors contributed to the review of the published material in this area, as well as the writing and revising of the article. SP is the guarantor.
Competing interests: All authors have completed the unified competing interest form at www.icmje.org/coi_disclosure.pdf (available on request from the corresponding author) and declare no support from any organisation for the submitted work; The Warwick Clinical Trials Unit benefited from facilities funded through the Birmingham Science City Translational Medicine Clinical Research and Infrastructure Trials Platform, with support from Advantage West Midlands. The Health Economics Research Centre receives funding from the National Institute of Health Research. SP started working on this article while employed by the National Perinatal Epidemiology Unit, University of Oxford, and the Health Economics Research Centre, University of Oxford, and funded by a UK Medical Research Council senior non-clinical research fellowship. AG is an NIHR senior investigator. They have no other relationships or activities that could appear to have influenced the submitted work.
Provenance and peer review: Commissioned; externally peer reviewed.
- ↵ Petrou S, Gray A. Economic evaluation alongside randomised clinical trials: design, conduct, analysis and reporting. BMJ 2011 ; 342 : d1548 . OpenUrl FREE Full Text
- ↵ Sculpher MJ, Claxton K, Drummond M, McCabe C. Whither trial-based economic evaluation for health care decision making? Health Econ 2006 ; 15 : 677 -87. OpenUrl CrossRef PubMed Web of Science
- ↵ Briggs A, Claxton C, Sculpher M. Decision modelling for health economic evaluation . Oxford University Press, 2006 .
- ↵ Gray A, Clarke P, Wolstenholme J, Wordsworth S. Applied methods of cost-effectiveness analysis in health care . Oxford University Press, 2010 .
- ↵ Drummond M, Manca A, Sculpher M. Increasing the generalizability of economic evaluations: recommendations for the design, analysis, and reporting of studies. Int J Technol Assess 2005 ; 21 : 165 -71. OpenUrl
- ↵ Drummond MF, Sculpher MJ, Torrance GW, O’Brien BJ, Stoddart G. Methods for the economic evaluation of health care programmes . 3rd ed. Oxford University Press, 2005 .
- ↵ Bojke L, Hornby E, Sculpher M. A comparison of the cost-effectiveness of pharmacotherapy or surgery (laparoscopic fundoplication) in the treatment of GORD. Pharmacoeconomics 2007 ; 25 : 829 -41. OpenUrl CrossRef PubMed
- ↵ Legood R, Gray A, Wolstenholme J, Moss S, LBC/HPV Cervical Screening Pilot Studies Group. The lifetime effects, costs and cost-effectiveness of using HPV testing to manage low-grade cytological abnormalities: results of the NHS pilot studies. BMJ 2006 ; 332 : 79 -83. OpenUrl Abstract / FREE Full Text
- ↵ Torrance GW, Feeny D. Utilities and quality-adjusted life years. Int J Technol Assess Health Care 1989 ; 5 : 559 -75. OpenUrl CrossRef PubMed
- ↵ Brennan A, Chick SE, Davies R. A taxonomy of model structures for economic evaluation of health technologies. Health Econ 2006 ; 15 : 1295 -310. OpenUrl CrossRef PubMed Web of Science
- ↵ Cooper K, Brailsford SC, Davies R. Choice of modelling technique for evaluating health care interventions. J Oper Res Soc 2007 ; 58 : 168 -76. OpenUrl Web of Science
- ↵ Brisson M, Edmunds WJ. Economic evaluation of vaccination programs: the impact of herd-immunity. Med Decis Making 2003 ; 23 : 76 -82. OpenUrl Abstract / FREE Full Text
- ↵ Barton P, Bryan S, Robinson S. Modelling in the economic evaluation of health care: selecting the appropriate approach. J Health Serv Res Policy 2004 ; 9 : 110 -8. OpenUrl Abstract / FREE Full Text
- ↵ Weinstein MC, O’Brien B, Hornberger J, Jackson J, Johannesson M, McCabe C, et al. Principles of good practice for decision analytic modeling in health-care evaluation: report of the ISPOR Task Force on Good Research Practices—modeling studies. Value Health 2003 ; 6 : 9 -17. OpenUrl CrossRef PubMed Web of Science
- ↵ NHS Centre for Reviews and Dissemination. Undertaking systematic reviews of research on effectiveness: CRD’s guidance for those carrying out or commissioning reviews . NHS CRD, University of York, 2001 .
- ↵ Philips Z, Ginnelly L, Sculpher M, Claxton K, Golder S, Riemsma R, et al. Review of guidelines for good practice in decision-analytic modelling in health technology assessment. Health Technol Assess 2004 ; 8 : iii -xi,1. OpenUrl PubMed
- ↵ Golder S, Glanville J, Ginnelly L. Populating decision-analytic models: the feasibility and efficiency of database searching for individual parameters. Int J Technol Assess Health Care 2005 ; 21 : 305 -11. OpenUrl PubMed Web of Science
- ↵ Coyle D, Lee LM. The problem of protocol driven costs in pharmacoeconomic analysis. Pharmacoeconomics 1998 ; 14 : 357 -63. OpenUrl CrossRef PubMed Web of Science
- ↵ Ades AE, Sutton A. Multiparameter evidence synthesis in epidemiology and medical decision-making: current approaches. J R Stat Soc 2006 ; 169 : 5 -35. OpenUrl CrossRef
- ↵ Weinstein MC. Recent developments in decision-analytic modelling for economic evaluation. Pharmacoeconomics 2006 ; 24 : 1043 -53. OpenUrl CrossRef PubMed Web of Science
- ↵ Fenwick E, O’Brien BJ, Briggs A. Cost-effectiveness acceptability curves: facts, fallacies and frequently asked questions. Health Econ 2004 ; 13 : 405 -15. OpenUrl CrossRef PubMed Web of Science
- ↵ Clarke PM, Gray AM, Briggs A, Farmer A, Fenn P, Stevens R, et al. A model to estimate the lifetime health outcomes of patients with type 2 diabetes: the United Kingdom Prospective Diabetes Study (UKPDS) outcomes model. Diabetologia 2004 ; 47 : 1747 -59. OpenUrl CrossRef PubMed Web of Science
- ↵ Mount Hood. Computer modeling of diabetes and its complications: a report on the fourth Mount Hood challenge meeting. Diabetes Care 2007 ; 30 : 1638 -46. OpenUrl Abstract / FREE Full Text
- ↵ Bojke L, Claxton K, Sculpher M, Palmer S. Characterizing structural uncertainty in decision analytic models: a review and application of methods. Value Health 2009 ; 12 : 739 -49. OpenUrl CrossRef
- ↵ Rothwell PM. Treating individuals 2. Subgroup analysis in randomised controlled trials: importance, indications, and interpretation. Lancet 2005 ; 365 : 176 -86. OpenUrl CrossRef PubMed Web of Science
- ↵ Mihaylova B, Briggs A, Armitage J, Parish S, Gray A, Collins R, et al. Cost-effectiveness of simvastatin in people at different levels of vascular disease risk: a randomised trial in 20 536 individuals. Lancet 2005 ; 365 : 1779 -85. OpenUrl CrossRef PubMed Web of Science
- ↵ Mihaylova B, Briggs A, Armitage J, Parish S, Gray, A, Collins R. Lifetime cost effectiveness of simvastatin in a range of risk groups and age groups derived from a randomised trial of 20 536 people. BMJ 2006 ; 333 : 1145 -8. OpenUrl Abstract / FREE Full Text
- ↵ Philips Z, Bojke L, Sculpher M, Claxton K, Golder S. Good practice guidelines for decision-analytic modelling in health technology assessment: a review and consolidation of quality assessment. Pharmacoeconomics 2006 ; 24 : 355 -71. OpenUrl CrossRef PubMed Web of Science
- ↵ Stout NK, Knudsen AB, Kong CK, McMahon PM, Gazelle GS. Calibration methods used in cancer simulation models and suggested reporting guidelines. Pharmacoeconomics 2009 ; 27 : 533 -45. OpenUrl CrossRef PubMed Web of Science
- ↵ Ades AE, Cliffe S. Markov chain Monte Carlo estimation of a multi-parameter decision model: consistency of evidence and the accurate assessment of uncertainty. Med Decis Making 2002 ; 22 : 359 -71. OpenUrl Abstract / FREE Full Text
- ↵ Claxton K, Ginnelly L, Sculpher M, Philips Z, Palmer S. A pilot study on the use of decision theory and value of information analysis as part of the NHS health technology assessment programme. Health Technol Assess 2004 ; 8 : 1 -103,iii. OpenUrl PubMed
- ↵ Philips Z, Claxton K, Palmer S. The half-life of truth: appropriate time horizons for research decisions? Med Decis Making 2008 ; 28 : 287 -99. OpenUrl Abstract / FREE Full Text
- ↵ Speight PM, Palmer S, Moles DR, Downer MC, Smith DH, Henriksson M, et al . The cost-effectiveness of screening for oral cancer in primary care. Health Technol Assess 2006 ; 10 : 1 -144,iii-iv. OpenUrl PubMed Web of Science
- ↵ Castelnuovo E, Thompson-Coon J, Pitt M, Cramp M, Siebert U, Price A, et al . The cost-effectiveness of testing for hepatitis C in former injecting drug users. Health Technol Assess 2006 ; 10 : iii -iv,ix-xii,1-93. OpenUrl PubMed Web of Science
- Harvard Library
- Research Guides
- Faculty of Arts & Sciences Libraries
Library Support for Qualitative Research
- Data Analysis
- Types of Interviews
- Recruiting & Engaging Participants
- Interview Questions
- Conducting Interviews
- Recording & Transcription
QDA Software
Coding and themeing the data, data visualization, testing or generating theories.
- Managing Interview Data
- Finding Extant Interviews
- Past Workshops on Interview Research
- Methodological Resources
- Remote & Virtual Fieldwork
- Data Management & Repositories
- Campus Access
- Free download available for Harvard Faculty of Arts and Sciences (FAS) affiliates
- Desktop access at Lamont Library Media Lab, 3rd floor
- Desktop access at Harvard Kennedy School Library (with HKS ID)
- Remote desktop access for Harvard affiliates from IQSS Computer Labs . Email them at [email protected] and ask for a new lab account and remote desktop access to NVivo.
- Virtual Desktop Infrastructure (VDI) access available to Harvard T.H. Chan School of Public Health affiliates.
Qualitative data analysis methods should flow from, or align with, the methodological paradigm chosen for your study, whether that paradigm is interpretivist, critical, positivist, or participative in nature (or a combination of these). Some established methods include Content Analysis, Critical Analysis, Discourse Analysis, Gestalt Analysis, Grounded Theory Analysis, Interpretive Analysis, Narrative Analysis, Normative Analysis, Phenomenological Analysis, Rhetorical Analysis, and Semiotic Analysis, among others. The following resources should help you navigate your methodological options and put into practice methods for coding, themeing, interpreting, and presenting your data.
- Users can browse content by topic, discipline, or format type (reference works, book chapters, definitions, etc.). SRM offers several research tools as well: a methods map, user-created reading lists, a project planner, and advice on choosing statistical tests.
- Abductive Coding: Theory Building and Qualitative (Re)Analysis by Vila-Henninger, et al. The authors recommend an abductive approach to guide qualitative researchers who are oriented towards theory-building. They outline a set of tactics for abductive analysis, including the generation of an abductive codebook, abductive data reduction through code equations, and in-depth abductive qualitative analysis.
- Analyzing and Interpreting Qualitative Research: After the Interview by Charles F. Vanover, Paul A. Mihas, and Johnny Saldana (Editors) Providing insight into the wide range of approaches available to the qualitative researcher and covering all steps in the research process, the authors utilize a consistent chapter structure that provides novice and seasoned researchers with pragmatic, "how-to" strategies. Each chapter author introduces the method, uses one of their own research projects as a case study of the method described, shows how the specific analytic method can be used in other types of studies, and concludes with three questions/activities to prompt class discussion or personal study.
- "Analyzing Qualitative Data." Theory Into Practice 39, no. 3 (2000): 146-54 by Margaret D. LeCompte This article walks readers though rules for unbiased data analysis and provides guidance for getting organized, finding items, creating stable sets of items, creating patterns, assembling structures, and conducting data validity checks.
- "Coding is Not a Dirty Word" in Chapter 1 (pp. 1–30) of Enhancing Qualitative and Mixed Methods Research with Technology by Shalin Hai-Jew (Editor) Current discourses in qualitative research, especially those situated in postmodernism, represent coding and the technology that assists with coding as reductive, lacking complexity, and detached from theory. In this chapter, the author presents a counter-narrative to this dominant discourse in qualitative research. The author argues that coding is not necessarily devoid of theory, nor does the use of software for data management and analysis automatically render scholarship theoretically lightweight or barren. A lack of deep analytical insight is a consequence not of software but of epistemology. Using examples informed by interpretive and critical approaches, the author demonstrates how NVivo can provide an effective tool for data management and analysis. The author also highlights ideas for critical and deconstructive approaches in qualitative inquiry while using NVivo. By troubling the positivist discourse of coding, the author seeks to create dialogic spaces that integrate theory with technology-driven data management and analysis, while maintaining the depth and rigor of qualitative research.
- The Coding Manual for Qualitative Researchers by Johnny Saldana An in-depth guide to the multiple approaches available for coding qualitative data. Clear, practical and authoritative, the book profiles 32 coding methods that can be applied to a range of research genres from grounded theory to phenomenology to narrative inquiry. For each approach, Saldaña discusses the methods, origins, a description of the method, practical applications, and a clearly illustrated example with analytic follow-up. Essential reading across the social sciences.
- Flexible Coding of In-depth Interviews: A Twenty-first-century Approach by Nicole M. Deterding and Mary C. Waters The authors suggest steps in data organization and analysis to better utilize qualitative data analysis technologies and support rigorous, transparent, and flexible analysis of in-depth interview data.
- From the Editors: What Grounded Theory is Not by Roy Suddaby Walks readers through common misconceptions that hinder grounded theory studies, reinforcing the two key concepts of the grounded theory approach: (1) constant comparison of data gathered throughout the data collection process and (2) the determination of which kinds of data to sample in succession based on emergent themes (i.e., "theoretical sampling").
- “Good enough” methods for life-story analysis, by Wendy Luttrell. In Quinn N. (Ed.), Finding culture in talk (pp. 243–268). Demonstrates for researchers of culture and consciousness who use narrative how to concretely document reflexive processes in terms of where, how and why particular decisions are made at particular stages of the research process.
- The Ethnographic Interview by James P. Spradley “Spradley wrote this book for the professional and student who have never done ethnographic fieldwork (p. 231) and for the professional ethnographer who is interested in adapting the author’s procedures (p. iv) ... Steps 6 and 8 explain lucidly how to construct a domain and a taxonomic analysis” (excerpted from book review by James D. Sexton, 1980). See also: Presentation slides on coding and themeing your data, derived from Saldana, Spradley, and LeCompte Click to request access.
- Qualitative Data Analysis by Matthew B. Miles; A. Michael Huberman A practical sourcebook for researchers who make use of qualitative data, presenting the current state of the craft in the design, testing, and use of qualitative analysis methods. Strong emphasis is placed on data displays matrices and networks that go beyond ordinary narrative text. Each method of data display and analysis is described and illustrated.
- "A Survey of Qualitative Data Analytic Methods" in Chapter 4 (pp. 89–138) of Fundamentals of Qualitative Research by Johnny Saldana Provides an in-depth introduction to coding as a heuristic, particularly focusing on process coding, in vivo coding, descriptive coding, values coding, dramaturgical coding, and versus coding. Includes advice on writing analytic memos, developing categories, and themeing data.
- "Thematic Networks: An Analytic Tool for Qualitative Research." Qualitative Research : QR, 1(3), 385–405 by Jennifer Attride-Stirling Details a technique for conducting thematic analysis of qualitative material, presenting a step-by-step guide of the analytic process, with the aid of an empirical example. The analytic method presented employs established, well-known techniques; the article proposes that thematic analyses can be usefully aided by and presented as thematic networks.
- Using Thematic Analysis in Psychology by Virginia Braun and Victoria Clark Walks readers through the process of reflexive thematic analysis, step by step. The method may be adapted in fields outside of psychology as relevant. Pair this with One Size Fits All? What Counts as Quality Practice in Reflexive Thematic Analysis? by Virginia Braun and Victoria Clark
Data visualization can be employed formatively, to aid your data analysis, or summatively, to present your findings. Many qualitative data analysis (QDA) software platforms, such as NVivo , feature search functionality and data visualization options within them to aid data analysis during the formative stages of your project.
For expert assistance creating data visualizations to present your research, Harvard Library offers Visualization Support . Get help and training with data visualization design and tools—such as Tableau—for the Harvard community. Workshops and one-on-one consultations are also available.
The quality of your data analysis depends on how you situate what you learn within a wider body of knowledge. Consider the following advice:
A good literature review has many obvious virtues. It enables the investigator to define problems and assess data. It provides the concepts on which percepts depend. But the literature review has a special importance for the qualitative researcher. This consists of its ability to sharpen his or her capacity for surprise (Lazarsfeld, 1972b). The investigator who is well versed in the literature now has a set of expectations the data can defy. Counterexpectational data are conspicuous, readable, and highly provocative data. They signal the existence of unfulfilled theoretical assumptions, and these are, as Kuhn (1962) has noted, the very origins of intellectual innovation. A thorough review of the literature is, to this extent, a way to manufacture distance. It is a way to let the data of one's research project take issue with the theory of one's field.
- McCracken, G. (1988), The Long Interview, Sage: Newbury Park, CA, p. 31
Once you have coalesced around a theory, realize that a theory should reveal rather than color your discoveries. Allow your data to guide you to what's most suitable. Grounded theory researchers may develop their own theory where current theories fail to provide insight. This guide on Theoretical Models from Alfaisal University Library provides a helpful overview on using theory.
If you'd like to supplement what you learned about relevant theories through your coursework and literature review, try these sources:
- Annual Reviews Review articles sum up the latest research in many fields, including social sciences, biomedicine, life sciences, and physical sciences. These are timely collections of critical reviews written by leading scientists.
- HOLLIS - search for resources on theories in your field Modify this example search by entering the name of your field in place of "your discipline," then hit search.
- Oxford Bibliographies Written and reviewed by academic experts, every article in this database is an authoritative guide to the current scholarship in a variety of fields, containing original commentary and annotations.
- ProQuest Dissertations & Theses (PQDT) Indexes dissertations and masters' theses from most North American graduate schools as well as some European universities. Provides full text for most indexed dissertations from 1990-present.
- Very Short Introductions Launched by Oxford University Press in 1995, Very Short Introductions offer concise introductions to a diverse range of subjects from Climate to Consciousness, Game Theory to Ancient Warfare, Privacy to Islamic History, Economics to Literary Theory.
- << Previous: Recording & Transcription
- Next: Managing Interview Data >>
Except where otherwise noted, this work is subject to a Creative Commons Attribution 4.0 International License , which allows anyone to share and adapt our material as long as proper attribution is given. For details and exceptions, see the Harvard Library Copyright Policy ©2021 Presidents and Fellows of Harvard College.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Springer Nature - PMC COVID-19 Collection
Data Science and Analytics: An Overview from Data-Driven Smart Computing, Decision-Making and Applications Perspective
Iqbal h. sarker.
1 Swinburne University of Technology, Melbourne, VIC 3122 Australia
2 Department of Computer Science and Engineering, Chittagong University of Engineering & Technology, Chittagong, 4349 Bangladesh
The digital world has a wealth of data, such as internet of things (IoT) data, business data, health data, mobile data, urban data, security data, and many more, in the current age of the Fourth Industrial Revolution (Industry 4.0 or 4IR). Extracting knowledge or useful insights from these data can be used for smart decision-making in various applications domains. In the area of data science, advanced analytics methods including machine learning modeling can provide actionable insights or deeper knowledge about data, which makes the computing process automatic and smart. In this paper, we present a comprehensive view on “Data Science” including various types of advanced analytics methods that can be applied to enhance the intelligence and capabilities of an application through smart decision-making in different scenarios. We also discuss and summarize ten potential real-world application domains including business, healthcare, cybersecurity, urban and rural data science, and so on by taking into account data-driven smart computing and decision making. Based on this, we finally highlight the challenges and potential research directions within the scope of our study. Overall, this paper aims to serve as a reference point on data science and advanced analytics to the researchers and decision-makers as well as application developers, particularly from the data-driven solution point of view for real-world problems.
Introduction
We are living in the age of “data science and advanced analytics”, where almost everything in our daily lives is digitally recorded as data [ 17 ]. Thus the current electronic world is a wealth of various kinds of data, such as business data, financial data, healthcare data, multimedia data, internet of things (IoT) data, cybersecurity data, social media data, etc [ 112 ]. The data can be structured, semi-structured, or unstructured, which increases day by day [ 105 ]. Data science is typically a “concept to unify statistics, data analysis, and their related methods” to understand and analyze the actual phenomena with data. According to Cao et al. [ 17 ] “data science is the science of data” or “data science is the study of data”, where a data product is a data deliverable, or data-enabled or guided, which can be a discovery, prediction, service, suggestion, insight into decision-making, thought, model, paradigm, tool, or system. The popularity of “Data science” is increasing day-by-day, which is shown in Fig. Fig.1 1 according to Google Trends data over the last 5 years [ 36 ]. In addition to data science, we have also shown the popularity trends of the relevant areas such as “Data analytics”, “Data mining”, “Big data”, “Machine learning” in the figure. According to Fig. Fig.1, 1 , the popularity indication values for these data-driven domains, particularly “Data science”, and “Machine learning” are increasing day-by-day. This statistical information and the applicability of the data-driven smart decision-making in various real-world application areas, motivate us to study briefly on “Data science” and machine-learning-based “Advanced analytics” in this paper.

The worldwide popularity score of data science comparing with relevant areas in a range of 0 (min) to 100 (max) over time where x -axis represents the timestamp information and y -axis represents the corresponding score
Usually, data science is the field of applying advanced analytics methods and scientific concepts to derive useful business information from data. The emphasis of advanced analytics is more on anticipating the use of data to detect patterns to determine what is likely to occur in the future. Basic analytics offer a description of data in general, while advanced analytics is a step forward in offering a deeper understanding of data and helping to analyze granular data, which we are interested in. In the field of data science, several types of analytics are popular, such as "Descriptive analytics" which answers the question of what happened; "Diagnostic analytics" which answers the question of why did it happen; "Predictive analytics" which predicts what will happen in the future; and "Prescriptive analytics" which prescribes what action should be taken, discussed briefly in “ Advanced analytics methods and smart computing ”. Such advanced analytics and decision-making based on machine learning techniques [ 105 ], a major part of artificial intelligence (AI) [ 102 ] can also play a significant role in the Fourth Industrial Revolution (Industry 4.0) due to its learning capability for smart computing as well as automation [ 121 ].
Although the area of “data science” is huge, we mainly focus on deriving useful insights through advanced analytics, where the results are used to make smart decisions in various real-world application areas. For this, various advanced analytics methods such as machine learning modeling, natural language processing, sentiment analysis, neural network, or deep learning analysis can provide deeper knowledge about data, and thus can be used to develop data-driven intelligent applications. More specifically, regression analysis, classification, clustering analysis, association rules, time-series analysis, sentiment analysis, behavioral patterns, anomaly detection, factor analysis, log analysis, and deep learning which is originated from the artificial neural network, are taken into account in our study. These machine learning-based advanced analytics methods are discussed briefly in “ Advanced analytics methods and smart computing ”. Thus, it’s important to understand the principles of various advanced analytics methods mentioned above and their applicability to apply in various real-world application areas. For instance, in our earlier paper Sarker et al. [ 114 ], we have discussed how data science and machine learning modeling can play a significant role in the domain of cybersecurity for making smart decisions and to provide data-driven intelligent security services. In this paper, we broadly take into account the data science application areas and real-world problems in ten potential domains including the area of business data science, health data science, IoT data science, behavioral data science, urban data science, and so on, discussed briefly in “ Real-world application domains ”.
Based on the importance of machine learning modeling to extract the useful insights from the data mentioned above and data-driven smart decision-making, in this paper, we present a comprehensive view on “Data Science” including various types of advanced analytics methods that can be applied to enhance the intelligence and the capabilities of an application. The key contribution of this study is thus understanding data science modeling, explaining different analytic methods for solution perspective and their applicability in various real-world data-driven applications areas mentioned earlier. Overall, the purpose of this paper is, therefore, to provide a basic guide or reference for those academia and industry people who want to study, research, and develop automated and intelligent applications or systems based on smart computing and decision making within the area of data science.
The main contributions of this paper are summarized as follows:
- To define the scope of our study towards data-driven smart computing and decision-making in our real-world life. We also make a brief discussion on the concept of data science modeling from business problems to data product and automation, to understand its applicability and provide intelligent services in real-world scenarios.
- To provide a comprehensive view on data science including advanced analytics methods that can be applied to enhance the intelligence and the capabilities of an application.
- To discuss the applicability and significance of machine learning-based analytics methods in various real-world application areas. We also summarize ten potential real-world application areas, from business to personalized applications in our daily life, where advanced analytics with machine learning modeling can be used to achieve the expected outcome.
- To highlight and summarize the challenges and potential research directions within the scope of our study.
The rest of the paper is organized as follows. The next section provides the background and related work and defines the scope of our study. The following section presents the concepts of data science modeling for building a data-driven application. After that, briefly discuss and explain different advanced analytics methods and smart computing. Various real-world application areas are discussed and summarized in the next section. We then highlight and summarize several research issues and potential future directions, and finally, the last section concludes this paper.
Background and Related Work
In this section, we first discuss various data terms and works related to data science and highlight the scope of our study.
Data Terms and Definitions
There is a range of key terms in the field, such as data analysis, data mining, data analytics, big data, data science, advanced analytics, machine learning, and deep learning, which are highly related and easily confusing. In the following, we define these terms and differentiate them with the term “Data Science” according to our goal.
The term “Data analysis” refers to the processing of data by conventional (e.g., classic statistical, empirical, or logical) theories, technologies, and tools for extracting useful information and for practical purposes [ 17 ]. The term “Data analytics”, on the other hand, refers to the theories, technologies, instruments, and processes that allow for an in-depth understanding and exploration of actionable data insight [ 17 ]. Statistical and mathematical analysis of the data is the major concern in this process. “Data mining” is another popular term over the last decade, which has a similar meaning with several other terms such as knowledge mining from data, knowledge extraction, knowledge discovery from data (KDD), data/pattern analysis, data archaeology, and data dredging. According to Han et al. [ 38 ], it should have been more appropriately named “knowledge mining from data”. Overall, data mining is defined as the process of discovering interesting patterns and knowledge from large amounts of data [ 38 ]. Data sources may include databases, data centers, the Internet or Web, other repositories of data, or data dynamically streamed through the system. “Big data” is another popular term nowadays, which may change the statistical and data analysis approaches as it has the unique features of “massive, high dimensional, heterogeneous, complex, unstructured, incomplete, noisy, and erroneous” [ 74 ]. Big data can be generated by mobile devices, social networks, the Internet of Things, multimedia, and many other new applications [ 129 ]. Several unique features including volume, velocity, variety, veracity, value (5Vs), and complexity are used to understand and describe big data [ 69 ].
In terms of analytics, basic analytics provides a summary of data whereas the term “Advanced Analytics” takes a step forward in offering a deeper understanding of data and helps to analyze granular data. Advanced analytics is characterized or defined as autonomous or semi-autonomous data or content analysis using advanced techniques and methods to discover deeper insights, predict or generate recommendations, typically beyond traditional business intelligence or analytics. “Machine learning”, a branch of artificial intelligence (AI), is one of the major techniques used in advanced analytics which can automate analytical model building [ 112 ]. This is focused on the premise that systems can learn from data, recognize trends, and make decisions, with minimal human involvement [ 38 , 115 ]. “Deep Learning” is a subfield of machine learning that discusses algorithms inspired by the human brain’s structure and the function called artificial neural networks [ 38 , 139 ].
Unlike the above data-related terms, “Data science” is an umbrella term that encompasses advanced data analytics, data mining, machine, and deep learning modeling, and several other related disciplines like statistics, to extract insights or useful knowledge from the datasets and transform them into actionable business strategies. In [ 17 ], Cao et al. defined data science from the disciplinary perspective as “data science is a new interdisciplinary field that synthesizes and builds on statistics, informatics, computing, communication, management, and sociology to study data and its environments (including domains and other contextual aspects, such as organizational and social aspects) to transform data to insights and decisions by following a data-to-knowledge-to-wisdom thinking and methodology”. In “ Understanding data science modeling ”, we briefly discuss the data science modeling from a practical perspective starting from business problems to data products that can assist the data scientists to think and work in a particular real-world problem domain within the area of data science and analytics.
Related Work
In the area, several papers have been reviewed by the researchers based on data science and its significance. For example, the authors in [ 19 ] identify the evolving field of data science and its importance in the broader knowledge environment and some issues that differentiate data science and informatics issues from conventional approaches in information sciences. Donoho et al. [ 27 ] present 50 years of data science including recent commentary on data science in mass media, and on how/whether data science varies from statistics. The authors formally conceptualize the theory-guided data science (TGDS) model in [ 53 ] and present a taxonomy of research themes in TGDS. Cao et al. include a detailed survey and tutorial on the fundamental aspects of data science in [ 17 ], which considers the transition from data analysis to data science, the principles of data science, as well as the discipline and competence of data education.
Besides, the authors include a data science analysis in [ 20 ], which aims to provide a realistic overview of the use of statistical features and related data science methods in bioimage informatics. The authors in [ 61 ] study the key streams of data science algorithm use at central banks and show how their popularity has risen over time. This research contributes to the creation of a research vector on the role of data science in central banking. In [ 62 ], the authors provide an overview and tutorial on the data-driven design of intelligent wireless networks. The authors in [ 87 ] provide a thorough understanding of computational optimal transport with application to data science. In [ 97 ], the authors present data science as theoretical contributions in information systems via text analytics.
Unlike the above recent studies, in this paper, we concentrate on the knowledge of data science including advanced analytics methods, machine learning modeling, real-world application domains, and potential research directions within the scope of our study. The advanced analytics methods based on machine learning techniques discussed in this paper can be applied to enhance the capabilities of an application in terms of data-driven intelligent decision making and automation in the final data product or systems.
Understanding Data Science Modeling
In this section, we briefly discuss how data science can play a significant role in the real-world business process. For this, we first categorize various types of data and then discuss the major steps of data science modeling starting from business problems to data product and automation.
Types of Real-World Data
Typically, to build a data-driven real-world system in a particular domain, the availability of data is the key [ 17 , 112 , 114 ]. The data can be in different types such as (i) Structured—that has a well-defined data structure and follows a standard order, examples are names, dates, addresses, credit card numbers, stock information, geolocation, etc.; (ii) Unstructured—has no pre-defined format or organization, examples are sensor data, emails, blog entries, wikis, and word processing documents, PDF files, audio files, videos, images, presentations, web pages, etc.; (iii) Semi-structured—has elements of both the structured and unstructured data containing certain organizational properties, examples are HTML, XML, JSON documents, NoSQL databases, etc.; and (iv) Metadata—that represents data about the data, examples are author, file type, file size, creation date and time, last modification date and time, etc. [ 38 , 105 ].
In the area of data science, researchers use various widely-used datasets for different purposes. These are, for example, cybersecurity datasets such as NSL-KDD [ 127 ], UNSW-NB15 [ 79 ], Bot-IoT [ 59 ], ISCX’12 [ 15 ], CIC-DDoS2019 [ 22 ], etc., smartphone datasets such as phone call logs [ 88 , 110 ], mobile application usages logs [ 124 , 149 ], SMS Log [ 28 ], mobile phone notification logs [ 77 ] etc., IoT data [ 56 , 11 , 64 ], health data such as heart disease [ 99 ], diabetes mellitus [ 86 , 147 ], COVID-19 [ 41 , 78 ], etc., agriculture and e-commerce data [ 128 , 150 ], and many more in various application domains. In “ Real-world application domains ”, we discuss ten potential real-world application domains of data science and analytics by taking into account data-driven smart computing and decision making, which can help the data scientists and application developers to explore more in various real-world issues.
Overall, the data used in data-driven applications can be any of the types mentioned above, and they can differ from one application to another in the real world. Data science modeling, which is briefly discussed below, can be used to analyze such data in a specific problem domain and derive insights or useful information from the data to build a data-driven model or data product.
Steps of Data Science Modeling
Data science is typically an umbrella term that encompasses advanced data analytics, data mining, machine, and deep learning modeling, and several other related disciplines like statistics, to extract insights or useful knowledge from the datasets and transform them into actionable business strategies, mentioned earlier in “ Background and related work ”. In this section, we briefly discuss how data science can play a significant role in the real-world business process. Figure Figure2 2 shows an example of data science modeling starting from real-world data to data-driven product and automation. In the following, we briefly discuss each module of the data science process.
- Understanding business problems: This involves getting a clear understanding of the problem that is needed to solve, how it impacts the relevant organization or individuals, the ultimate goals for addressing it, and the relevant project plan. Thus to understand and identify the business problems, the data scientists formulate relevant questions while working with the end-users and other stakeholders. For instance, how much/many, which category/group, is the behavior unrealistic/abnormal, which option should be taken, what action, etc. could be relevant questions depending on the nature of the problems. This helps to get a better idea of what business needs and what we should be extracted from data. Such business knowledge can enable organizations to enhance their decision-making process, is known as “Business Intelligence” [ 65 ]. Identifying the relevant data sources that can help to answer the formulated questions and what kinds of actions should be taken from the trends that the data shows, is another important task associated with this stage. Once the business problem has been clearly stated, the data scientist can define the analytic approach to solve the problem.
- Understanding data: As we know that data science is largely driven by the availability of data [ 114 ]. Thus a sound understanding of the data is needed towards a data-driven model or system. The reason is that real-world data sets are often noisy, missing values, have inconsistencies, or other data issues, which are needed to handle effectively [ 101 ]. To gain actionable insights, the appropriate data or the quality of the data must be sourced and cleansed, which is fundamental to any data science engagement. For this, data assessment that evaluates what data is available and how it aligns to the business problem could be the first step in data understanding. Several aspects such as data type/format, the quantity of data whether it is sufficient or not to extract the useful knowledge, data relevance, authorized access to data, feature or attribute importance, combining multiple data sources, important metrics to report the data, etc. are needed to take into account to clearly understand the data for a particular business problem. Overall, the data understanding module involves figuring out what data would be best needed and the best ways to acquire it.
- Data pre-processing and exploration: Exploratory data analysis is defined in data science as an approach to analyzing datasets to summarize their key characteristics, often with visual methods [ 135 ]. This examines a broad data collection to discover initial trends, attributes, points of interest, etc. in an unstructured manner to construct meaningful summaries of the data. Thus data exploration is typically used to figure out the gist of data and to develop a first step assessment of its quality, quantity, and characteristics. A statistical model can be used or not, but primarily it offers tools for creating hypotheses by generally visualizing and interpreting the data through graphical representation such as a chart, plot, histogram, etc [ 72 , 91 ]. Before the data is ready for modeling, it’s necessary to use data summarization and visualization to audit the quality of the data and provide the information needed to process it. To ensure the quality of the data, the data pre-processing technique, which is typically the process of cleaning and transforming raw data [ 107 ] before processing and analysis is important. It also involves reformatting information, making data corrections, and merging data sets to enrich data. Thus, several aspects such as expected data, data cleaning, formatting or transforming data, dealing with missing values, handling data imbalance and bias issues, data distribution, search for outliers or anomalies in data and dealing with them, ensuring data quality, etc. could be the key considerations in this step.
- Machine learning modeling and evaluation: Once the data is prepared for building the model, data scientists design a model, algorithm, or set of models, to address the business problem. Model building is dependent on what type of analytics, e.g., predictive analytics, is needed to solve the particular problem, which is discussed briefly in “ Advanced analytics methods and smart computing ”. To best fits the data according to the type of analytics, different types of data-driven or machine learning models that have been summarized in our earlier paper Sarker et al. [ 105 ], can be built to achieve the goal. Data scientists typically separate training and test subsets of the given dataset usually dividing in the ratio of 80:20 or data considering the most popular k -folds data splitting method [ 38 ]. This is to observe whether the model performs well or not on the data, to maximize the model performance. Various model validation and assessment metrics, such as error rate, accuracy, true positive, false positive, true negative, false negative, precision, recall, f-score, ROC (receiver operating characteristic curve) analysis, applicability analysis, etc. [ 38 , 115 ] are used to measure the model performance, which can guide the data scientists to choose or design the learning method or model. Besides, machine learning experts or data scientists can take into account several advanced analytics such as feature engineering, feature selection or extraction methods, algorithm tuning, ensemble methods, modifying existing algorithms, or designing new algorithms, etc. to improve the ultimate data-driven model to solve a particular business problem through smart decision making.
- Data product and automation: A data product is typically the output of any data science activity [ 17 ]. A data product, in general terms, is a data deliverable, or data-enabled or guide, which can be a discovery, prediction, service, suggestion, insight into decision-making, thought, model, paradigm, tool, application, or system that process data and generate results. Businesses can use the results of such data analysis to obtain useful information like churn (a measure of how many customers stop using a product) prediction and customer segmentation, and use these results to make smarter business decisions and automation. Thus to make better decisions in various business problems, various machine learning pipelines and data products can be developed. To highlight this, we summarize several potential real-world data science application areas in “ Real-world application domains ”, where various data products can play a significant role in relevant business problems to make them smart and automate.
Overall, we can conclude that data science modeling can be used to help drive changes and improvements in business practices. The interesting part of the data science process indicates having a deeper understanding of the business problem to solve. Without that, it would be much harder to gather the right data and extract the most useful information from the data for making decisions to solve the problem. In terms of role, “Data Scientists” typically interpret and manage data to uncover the answers to major questions that help organizations to make objective decisions and solve complex problems. In a summary, a data scientist proactively gathers and analyzes information from multiple sources to better understand how the business performs, and designs machine learning or data-driven tools/methods, or algorithms, focused on advanced analytics, which can make today’s computing process smarter and intelligent, discussed briefly in the following section.

An example of data science modeling from real-world data to data-driven system and decision making
Advanced Analytics Methods and Smart Computing
As mentioned earlier in “ Background and related work ”, basic analytics provides a summary of data whereas advanced analytics takes a step forward in offering a deeper understanding of data and helps in granular data analysis. For instance, the predictive capabilities of advanced analytics can be used to forecast trends, events, and behaviors. Thus, “advanced analytics” can be defined as the autonomous or semi-autonomous analysis of data or content using advanced techniques and methods to discover deeper insights, make predictions, or produce recommendations, where machine learning-based analytical modeling is considered as the key technologies in the area. In the following section, we first summarize various types of analytics and outcome that are needed to solve the associated business problems, and then we briefly discuss machine learning-based analytical modeling.
Types of Analytics and Outcome
In the real-world business process, several key questions such as “What happened?”, “Why did it happen?”, “What will happen in the future?”, “What action should be taken?” are common and important. Based on these questions, in this paper, we categorize and highlight the analytics into four types such as descriptive, diagnostic, predictive, and prescriptive, which are discussed below.
- Descriptive analytics: It is the interpretation of historical data to better understand the changes that have occurred in a business. Thus descriptive analytics answers the question, “what happened in the past?” by summarizing past data such as statistics on sales and operations or marketing strategies, use of social media, and engagement with Twitter, Linkedin or Facebook, etc. For instance, using descriptive analytics through analyzing trends, patterns, and anomalies, etc., customers’ historical shopping data can be used to predict the probability of a customer purchasing a product. Thus, descriptive analytics can play a significant role to provide an accurate picture of what has occurred in a business and how it relates to previous times utilizing a broad range of relevant business data. As a result, managers and decision-makers can pinpoint areas of strength and weakness in their business, and eventually can take more effective management strategies and business decisions.
- Diagnostic analytics: It is a form of advanced analytics that examines data or content to answer the question, “why did it happen?” The goal of diagnostic analytics is to help to find the root cause of the problem. For example, the human resource management department of a business organization may use these diagnostic analytics to find the best applicant for a position, select them, and compare them to other similar positions to see how well they perform. In a healthcare example, it might help to figure out whether the patients’ symptoms such as high fever, dry cough, headache, fatigue, etc. are all caused by the same infectious agent. Overall, diagnostic analytics enables one to extract value from the data by posing the right questions and conducting in-depth investigations into the answers. It is characterized by techniques such as drill-down, data discovery, data mining, and correlations.
- Predictive analytics: Predictive analytics is an important analytical technique used by many organizations for various purposes such as to assess business risks, anticipate potential market patterns, and decide when maintenance is needed, to enhance their business. It is a form of advanced analytics that examines data or content to answer the question, “what will happen in the future?” Thus, the primary goal of predictive analytics is to identify and typically answer this question with a high degree of probability. Data scientists can use historical data as a source to extract insights for building predictive models using various regression analyses and machine learning techniques, which can be used in various application domains for a better outcome. Companies, for example, can use predictive analytics to minimize costs by better anticipating future demand and changing output and inventory, banks and other financial institutions to reduce fraud and risks by predicting suspicious activity, medical specialists to make effective decisions through predicting patients who are at risk of diseases, retailers to increase sales and customer satisfaction through understanding and predicting customer preferences, manufacturers to optimize production capacity through predicting maintenance requirements, and many more. Thus predictive analytics can be considered as the core analytical method within the area of data science.
- Prescriptive analytics: Prescriptive analytics focuses on recommending the best way forward with actionable information to maximize overall returns and profitability, which typically answer the question, “what action should be taken?” In business analytics, prescriptive analytics is considered the final step. For its models, prescriptive analytics collects data from several descriptive and predictive sources and applies it to the decision-making process. Thus, we can say that it is related to both descriptive analytics and predictive analytics, but it emphasizes actionable insights instead of data monitoring. In other words, it can be considered as the opposite of descriptive analytics, which examines decisions and outcomes after the fact. By integrating big data, machine learning, and business rules, prescriptive analytics helps organizations to make more informed decisions to produce results that drive the most successful business decisions.
In summary, to clarify what happened and why it happened, both descriptive analytics and diagnostic analytics look at the past. Historical data is used by predictive analytics and prescriptive analytics to forecast what will happen in the future and what steps should be taken to impact those effects. In Table Table1, 1 , we have summarized these analytics methods with examples. Forward-thinking organizations in the real world can jointly use these analytical methods to make smart decisions that help drive changes in business processes and improvements. In the following, we discuss how machine learning techniques can play a big role in these analytical methods through their learning capabilities from the data.
Various types of analytical methods with examples
| Analytical methods | Data-driven model building | Examples |
|---|---|---|
| Descriptive analytics | Answer the question, “what happened in the past”? | Summarising past events, e.g., sales, business data, social media usage, reporting general trends, etc. |
| Diagnostic analytics | Answer the question, “why did it happen?” | Identify anomalies and determine casual relationships, to find out business loss, identifying the influence of medications, etc. |
| Predictive analytics | Answer the question, “what will happen in the future?” | Predicting customer preferences, recommending products, identifying possible security breaches, predicting staff and resource needs, etc. |
| Prescriptive analytics | Answer the question, “what action should be taken?” | Improving business management, maintenance, improving patient care and healthcare administration, determining optimal marketing strategies, etc. |
Machine Learning Based Analytical Modeling
In this section, we briefly discuss various advanced analytics methods based on machine learning modeling, which can make the computing process smart through intelligent decision-making in a business process. Figure Figure3 3 shows a general structure of a machine learning-based predictive modeling considering both the training and testing phase. In the following, we discuss a wide range of methods such as regression and classification analysis, association rule analysis, time-series analysis, behavioral analysis, log analysis, and so on within the scope of our study.

A general structure of a machine learning based predictive model considering both the training and testing phase
Regression Analysis
In data science, one of the most common statistical approaches used for predictive modeling and data mining tasks is regression techniques [ 38 ]. Regression analysis is a form of supervised machine learning that examines the relationship between a dependent variable (target) and independent variables (predictor) to predict continuous-valued output [ 105 , 117 ]. The following equations Eqs. 1 , 2 , and 3 [ 85 , 105 ] represent the simple, multiple or multivariate, and polynomial regressions respectively, where x represents independent variable and y is the predicted/target output mentioned above:
Regression analysis is typically conducted for one of two purposes: to predict the value of the dependent variable in the case of individuals for whom some knowledge relating to the explanatory variables is available, or to estimate the effect of some explanatory variable on the dependent variable, i.e., finding the relationship of causal influence between the variables. Linear regression cannot be used to fit non-linear data and may cause an underfitting problem. In that case, polynomial regression performs better, however, increases the model complexity. The regularization techniques such as Ridge, Lasso, Elastic-Net, etc. [ 85 , 105 ] can be used to optimize the linear regression model. Besides, support vector regression, decision tree regression, random forest regression techniques [ 85 , 105 ] can be used for building effective regression models depending on the problem type, e.g., non-linear tasks. Financial forecasting or prediction, cost estimation, trend analysis, marketing, time-series estimation, drug response modeling, etc. are some examples where the regression models can be used to solve real-world problems in the domain of data science and analytics.
Classification Analysis
Classification is one of the most widely used and best-known data science processes. This is a form of supervised machine learning approach that also refers to a predictive modeling problem in which a class label is predicted for a given example [ 38 ]. Spam identification, such as ‘spam’ and ‘not spam’ in email service providers, can be an example of a classification problem. There are several forms of classification analysis available in the area such as binary classification—which refers to the prediction of one of two classes; multi-class classification—which involves the prediction of one of more than two classes; multi-label classification—a generalization of multiclass classification in which the problem’s classes are organized hierarchically [ 105 ].
Several popular classification techniques, such as k-nearest neighbors [ 5 ], support vector machines [ 55 ], navies Bayes [ 49 ], adaptive boosting [ 32 ], extreme gradient boosting [ 85 ], logistic regression [ 66 ], decision trees ID3 [ 92 ], C4.5 [ 93 ], and random forests [ 13 ] exist to solve classification problems. The tree-based classification technique, e.g., random forest considering multiple decision trees, performs better than others to solve real-world problems in many cases as due to its capability of producing logic rules [ 103 , 115 ]. Figure Figure4 4 shows an example of a random forest structure considering multiple decision trees. In addition, BehavDT recently proposed by Sarker et al. [ 109 ], and IntrudTree [ 106 ] can be used for building effective classification or prediction models in the relevant tasks within the domain of data science and analytics.

An example of a random forest structure considering multiple decision trees
Cluster Analysis
Clustering is a form of unsupervised machine learning technique and is well-known in many data science application areas for statistical data analysis [ 38 ]. Usually, clustering techniques search for the structures inside a dataset and, if the classification is not previously identified, classify homogeneous groups of cases. This means that data points are identical to each other within a cluster, and different from data points in another cluster. Overall, the purpose of cluster analysis is to sort various data points into groups (or clusters) that are homogeneous internally and heterogeneous externally [ 105 ]. To gain insight into how data is distributed in a given dataset or as a preprocessing phase for other algorithms, clustering is often used. Data clustering, for example, assists with customer shopping behavior, sales campaigns, and retention of consumers for retail businesses, anomaly detection, etc.
Many clustering algorithms with the ability to group data have been proposed in machine learning and data science literature [ 98 , 138 , 141 ]. In our earlier paper Sarker et al. [ 105 ], we have summarized this based on several perspectives, such as partitioning methods, density-based methods, hierarchical-based methods, model-based methods, etc. In the literature, the popular K-means [ 75 ], K-Mediods [ 84 ], CLARA [ 54 ] etc. are known as partitioning methods; DBSCAN [ 30 ], OPTICS [ 8 ] etc. are known as density-based methods; single linkage [ 122 ], complete linkage [ 123 ], etc. are known as hierarchical methods. In addition, grid-based clustering methods, such as STING [ 134 ], CLIQUE [ 2 ], etc.; model-based clustering such as neural network learning [ 141 ], GMM [ 94 ], SOM [ 18 , 104 ], etc.; constrained-based methods such as COP K-means [ 131 ], CMWK-Means [ 25 ], etc. are used in the area. Recently, Sarker et al. [ 111 ] proposed a hierarchical clustering method, BOTS [ 111 ] based on bottom-up agglomerative technique for capturing user’s similar behavioral characteristics over time. The key benefit of agglomerative hierarchical clustering is that the tree-structure hierarchy created by agglomerative clustering is more informative than an unstructured set of flat clusters, which can assist in better decision-making in relevant application areas in data science.
Association Rule Analysis
Association rule learning is known as a rule-based machine learning system, an unsupervised learning method is typically used to establish a relationship among variables. This is a descriptive technique often used to analyze large datasets for discovering interesting relationships or patterns. The association learning technique’s main strength is its comprehensiveness, as it produces all associations that meet user-specified constraints including minimum support and confidence value [ 138 ].
Association rules allow a data scientist to identify trends, associations, and co-occurrences between data sets inside large data collections. In a supermarket, for example, associations infer knowledge about the buying behavior of consumers for different items, which helps to change the marketing and sales plan. In healthcare, to better diagnose patients, physicians may use association guidelines. Doctors can assess the conditional likelihood of a given illness by comparing symptom associations in the data from previous cases using association rules and machine learning-based data analysis. Similarly, association rules are useful for consumer behavior analysis and prediction, customer market analysis, bioinformatics, weblog mining, recommendation systems, etc.
Several types of association rules have been proposed in the area, such as frequent pattern based [ 4 , 47 , 73 ], logic-based [ 31 ], tree-based [ 39 ], fuzzy-rules [ 126 ], belief rule [ 148 ] etc. The rule learning techniques such as AIS [ 3 ], Apriori [ 4 ], Apriori-TID and Apriori-Hybrid [ 4 ], FP-Tree [ 39 ], Eclat [ 144 ], RARM [ 24 ] exist to solve the relevant business problems. Apriori [ 4 ] is the most commonly used algorithm for discovering association rules from a given dataset among the association rule learning techniques [ 145 ]. The recent association rule-learning technique ABC-RuleMiner proposed in our earlier paper by Sarker et al. [ 113 ] could give significant results in terms of generating non-redundant rules that can be used for smart decision making according to human preferences, within the area of data science applications.
Time-Series Analysis and Forecasting
A time series is typically a series of data points indexed in time order particularly, by date, or timestamp [ 111 ]. Depending on the frequency, the time-series can be different types such as annually, e.g., annual budget, quarterly, e.g., expenditure, monthly, e.g., air traffic, weekly, e.g., sales quantity, daily, e.g., weather, hourly, e.g., stock price, minute-wise, e.g., inbound calls in a call center, and even second-wise, e.g., web traffic, and so on in relevant domains.
A mathematical method dealing with such time-series data, or the procedure of fitting a time series to a proper model is termed time-series analysis. Many different time series forecasting algorithms and analysis methods can be applied to extract the relevant information. For instance, to do time-series forecasting for future patterns, the autoregressive (AR) model [ 130 ] learns the behavioral trends or patterns of past data. Moving average (MA) [ 40 ] is another simple and common form of smoothing used in time series analysis and forecasting that uses past forecasted errors in a regression-like model to elaborate an averaged trend across the data. The autoregressive moving average (ARMA) [ 12 , 120 ] combines these two approaches, where autoregressive extracts the momentum and pattern of the trend and moving average capture the noise effects. The most popular and frequently used time-series model is the autoregressive integrated moving average (ARIMA) model [ 12 , 120 ]. ARIMA model, a generalization of an ARMA model, is more flexible than other statistical models such as exponential smoothing or simple linear regression. In terms of data, the ARMA model can only be used for stationary time-series data, while the ARIMA model includes the case of non-stationarity as well. Similarly, seasonal autoregressive integrated moving average (SARIMA), autoregressive fractionally integrated moving average (ARFIMA), autoregressive moving average model with exogenous inputs model (ARMAX model) are also used in time-series models [ 120 ].
In addition to the stochastic methods for time-series modeling and forecasting, machine and deep learning-based approach can be used for effective time-series analysis and forecasting. For instance, in our earlier paper, Sarker et al. [ 111 ] present a bottom-up clustering-based time-series analysis to capture the mobile usage behavioral patterns of the users. Figure Figure5 5 shows an example of producing aggregate time segments Seg_i from initial time slices TS_i based on similar behavioral characteristics that are used in our bottom-up clustering approach, where D represents the dominant behavior BH_i of the users, mentioned above [ 111 ]. The authors in [ 118 ], used a long short-term memory (LSTM) model, a kind of recurrent neural network (RNN) deep learning model, in forecasting time-series that outperform traditional approaches such as the ARIMA model. Time-series analysis is commonly used these days in various fields such as financial, manufacturing, business, social media, event data (e.g., clickstreams and system events), IoT and smartphone data, and generally in any applied science and engineering temporal measurement domain. Thus, it covers a wide range of application areas in data science.

An example of producing aggregate time segments from initial time slices based on similar behavioral characteristics
Opinion Mining and Sentiment Analysis
Sentiment analysis or opinion mining is the computational study of the opinions, thoughts, emotions, assessments, and attitudes of people towards entities such as products, services, organizations, individuals, issues, events, topics, and their attributes [ 71 ]. There are three kinds of sentiments: positive, negative, and neutral, along with more extreme feelings such as angry, happy and sad, or interested or not interested, etc. More refined sentiments to evaluate the feelings of individuals in various situations can also be found according to the problem domain.
Although the task of opinion mining and sentiment analysis is very challenging from a technical point of view, it’s very useful in real-world practice. For instance, a business always aims to obtain an opinion from the public or customers about its products and services to refine the business policy as well as a better business decision. It can thus benefit a business to understand the social opinion of their brand, product, or service. Besides, potential customers want to know what consumers believe they have when they use a service or purchase a product. Document-level, sentence level, aspect level, and concept level, are the possible levels of opinion mining in the area [ 45 ].
Several popular techniques such as lexicon-based including dictionary-based and corpus-based methods, machine learning including supervised and unsupervised learning, deep learning, and hybrid methods are used in sentiment analysis-related tasks [ 70 ]. To systematically define, extract, measure, and analyze affective states and subjective knowledge, it incorporates the use of statistics, natural language processing (NLP), machine learning as well as deep learning methods. Sentiment analysis is widely used in many applications, such as reviews and survey data, web and social media, and healthcare content, ranging from marketing and customer support to clinical practice. Thus sentiment analysis has a big influence in many data science applications, where public sentiment is involved in various real-world issues.
Behavioral Data and Cohort Analysis
Behavioral analytics is a recent trend that typically reveals new insights into e-commerce sites, online gaming, mobile and smartphone applications, IoT user behavior, and many more [ 112 ]. The behavioral analysis aims to understand how and why the consumers or users behave, allowing accurate predictions of how they are likely to behave in the future. For instance, it allows advertisers to make the best offers with the right client segments at the right time. Behavioral analytics, including traffic data such as navigation paths, clicks, social media interactions, purchase decisions, and marketing responsiveness, use the large quantities of raw user event information gathered during sessions in which people use apps, games, or websites. In our earlier papers Sarker et al. [ 101 , 111 , 113 ] we have discussed how to extract users phone usage behavioral patterns utilizing real-life phone log data for various purposes.
In the real-world scenario, behavioral analytics is often used in e-commerce, social media, call centers, billing systems, IoT systems, political campaigns, and other applications, to find opportunities for optimization to achieve particular outcomes. Cohort analysis is a branch of behavioral analytics that involves studying groups of people over time to see how their behavior changes. For instance, it takes data from a given data set (e.g., an e-commerce website, web application, or online game) and separates it into related groups for analysis. Various machine learning techniques such as behavioral data clustering [ 111 ], behavioral decision tree classification [ 109 ], behavioral association rules [ 113 ], etc. can be used in the area according to the goal. Besides, the concept of RecencyMiner, proposed in our earlier paper Sarker et al. [ 108 ] that takes into account recent behavioral patterns could be effective while analyzing behavioral data as it may not be static in the real-world changes over time.
Anomaly Detection or Outlier Analysis
Anomaly detection, also known as Outlier analysis is a data mining step that detects data points, events, and/or findings that deviate from the regularities or normal behavior of a dataset. Anomalies are usually referred to as outliers, abnormalities, novelties, noise, inconsistency, irregularities, and exceptions [ 63 , 114 ]. Techniques of anomaly detection may discover new situations or cases as deviant based on historical data through analyzing the data patterns. For instance, identifying fraud or irregular transactions in finance is an example of anomaly detection.
It is often used in preprocessing tasks for the deletion of anomalous or inconsistency in the real-world data collected from various data sources including user logs, devices, networks, and servers. For anomaly detection, several machine learning techniques can be used, such as k-nearest neighbors, isolation forests, cluster analysis, etc [ 105 ]. The exclusion of anomalous data from the dataset also results in a statistically significant improvement in accuracy during supervised learning [ 101 ]. However, extracting appropriate features, identifying normal behaviors, managing imbalanced data distribution, addressing variations in abnormal behavior or irregularities, the sparse occurrence of abnormal events, environmental variations, etc. could be challenging in the process of anomaly detection. Detection of anomalies can be applicable in a variety of domains such as cybersecurity analytics, intrusion detections, fraud detection, fault detection, health analytics, identifying irregularities, detecting ecosystem disturbances, and many more. This anomaly detection can be considered a significant task for building effective systems with higher accuracy within the area of data science.
Factor Analysis
Factor analysis is a collection of techniques for describing the relationships or correlations between variables in terms of more fundamental entities known as factors [ 23 ]. It’s usually used to organize variables into a small number of clusters based on their common variance, where mathematical or statistical procedures are used. The goals of factor analysis are to determine the number of fundamental influences underlying a set of variables, calculate the degree to which each variable is associated with the factors, and learn more about the existence of the factors by examining which factors contribute to output on which variables. The broad purpose of factor analysis is to summarize data so that relationships and patterns can be easily interpreted and understood [ 143 ].
Exploratory factor analysis (EFA) and confirmatory factor analysis (CFA) are the two most popular factor analysis techniques. EFA seeks to discover complex trends by analyzing the dataset and testing predictions, while CFA tries to validate hypotheses and uses path analysis diagrams to represent variables and factors [ 143 ]. Factor analysis is one of the algorithms for unsupervised machine learning that is used for minimizing dimensionality. The most common methods for factor analytics are principal components analysis (PCA), principal axis factoring (PAF), and maximum likelihood (ML) [ 48 ]. Methods of correlation analysis such as Pearson correlation, canonical correlation, etc. may also be useful in the field as they can quantify the statistical relationship between two continuous variables, or association. Factor analysis is commonly used in finance, marketing, advertising, product management, psychology, and operations research, and thus can be considered as another significant analytical method within the area of data science.
Log Analysis
Logs are commonly used in system management as logs are often the only data available that record detailed system runtime activities or behaviors in production [ 44 ]. Log analysis is thus can be considered as the method of analyzing, interpreting, and capable of understanding computer-generated records or messages, also known as logs. This can be device log, server log, system log, network log, event log, audit trail, audit record, etc. The process of creating such records is called data logging.
Logs are generated by a wide variety of programmable technologies, including networking devices, operating systems, software, and more. Phone call logs [ 88 , 110 ], SMS Logs [ 28 ], mobile apps usages logs [ 124 , 149 ], notification logs [ 77 ], game Logs [ 82 ], context logs [ 16 , 149 ], web logs [ 37 ], smartphone life logs [ 95 ], etc. are some examples of log data for smartphone devices. The main characteristics of these log data is that it contains users’ actual behavioral activities with their devices. Similar other log data can be search logs [ 50 , 133 ], application logs [ 26 ], server logs [ 33 ], network logs [ 57 ], event logs [ 83 ], network and security logs [ 142 ] etc.
Several techniques such as classification and tagging, correlation analysis, pattern recognition methods, anomaly detection methods, machine learning modeling, etc. [ 105 ] can be used for effective log analysis. Log analysis can assist in compliance with security policies and industry regulations, as well as provide a better user experience by encouraging the troubleshooting of technical problems and identifying areas where efficiency can be improved. For instance, web servers use log files to record data about website visitors. Windows event log analysis can help an investigator draw a timeline based on the logging information and the discovered artifacts. Overall, advanced analytics methods by taking into account machine learning modeling can play a significant role to extract insightful patterns from these log data, which can be used for building automated and smart applications, and thus can be considered as a key working area in data science.
Neural Networks and Deep Learning Analysis
Deep learning is a form of machine learning that uses artificial neural networks to create a computational architecture that learns from data by combining multiple processing layers, such as the input, hidden, and output layers [ 38 ]. The key benefit of deep learning over conventional machine learning methods is that it performs better in a variety of situations, particularly when learning from large datasets [ 114 , 140 ].
The most common deep learning algorithms are: multi-layer perceptron (MLP) [ 85 ], convolutional neural network (CNN or ConvNet) [ 67 ], long short term memory recurrent neural network (LSTM-RNN) [ 34 ]. Figure Figure6 6 shows a structure of an artificial neural network modeling with multiple processing layers. The Backpropagation technique [ 38 ] is used to adjust the weight values internally while building the model. Convolutional neural networks (CNNs) [ 67 ] improve on the design of traditional artificial neural networks (ANNs), which include convolutional layers, pooling layers, and fully connected layers. It is commonly used in a variety of fields, including natural language processing, speech recognition, image processing, and other autocorrelated data since it takes advantage of the two-dimensional (2D) structure of the input data. AlexNet [ 60 ], Xception [ 21 ], Inception [ 125 ], Visual Geometry Group (VGG) [ 42 ], ResNet [ 43 ], etc., and other advanced deep learning models based on CNN are also used in the field.

A structure of an artificial neural network modeling with multiple processing layers
In addition to CNN, recurrent neural network (RNN) architecture is another popular method used in deep learning. Long short-term memory (LSTM) is a popular type of recurrent neural network architecture used broadly in the area of deep learning. Unlike traditional feed-forward neural networks, LSTM has feedback connections. Thus, LSTM networks are well-suited for analyzing and learning sequential data, such as classifying, sorting, and predicting data based on time-series data. Therefore, when the data is in a sequential format, such as time, sentence, etc., LSTM can be used, and it is widely used in the areas of time-series analysis, natural language processing, speech recognition, and so on.
In addition to the most popular deep learning methods mentioned above, several other deep learning approaches [ 104 ] exist in the field for various purposes. The self-organizing map (SOM) [ 58 ], for example, uses unsupervised learning to represent high-dimensional data as a 2D grid map, reducing dimensionality. Another learning technique that is commonly used for dimensionality reduction and feature extraction in unsupervised learning tasks is the autoencoder (AE) [ 10 ]. Restricted Boltzmann machines (RBM) can be used for dimensionality reduction, classification, regression, collaborative filtering, feature learning, and topic modeling, according to [ 46 ]. A deep belief network (DBN) is usually made up of a backpropagation neural network and unsupervised networks like restricted Boltzmann machines (RBMs) or autoencoders (BPNN) [ 136 ]. A generative adversarial network (GAN) [ 35 ] is a deep learning network that can produce data with characteristics that are similar to the input data. Transfer learning is common worldwide presently because it can train deep neural networks with a small amount of data, which is usually the re-use of a pre-trained model on a new problem [ 137 ]. These deep learning methods can perform well, particularly, when learning from large-scale datasets [ 105 , 140 ]. In our previous article Sarker et al. [ 104 ], we have summarized a brief discussion of various artificial neural networks (ANN) and deep learning (DL) models mentioned above, which can be used in a variety of data science and analytics tasks.
Real-World Application Domains
Almost every industry or organization is impacted by data, and thus “Data Science” including advanced analytics with machine learning modeling can be used in business, marketing, finance, IoT systems, cybersecurity, urban management, health care, government policies, and every possible industries, where data gets generated. In the following, we discuss ten most popular application areas based on data science and analytics.
- Business or financial data science: In general, business data science can be considered as the study of business or e-commerce data to obtain insights about a business that can typically lead to smart decision-making as well as taking high-quality actions [ 90 ]. Data scientists can develop algorithms or data-driven models predicting customer behavior, identifying patterns and trends based on historical business data, which can help companies to reduce costs, improve service delivery, and generate recommendations for better decision-making. Eventually, business automation, intelligence, and efficiency can be achieved through the data science process discussed earlier, where various advanced analytics methods and machine learning modeling based on the collected data are the keys. Many online retailers, such as Amazon [ 76 ], can improve inventory management, avoid out-of-stock situations, and optimize logistics and warehousing using predictive modeling based on machine learning techniques [ 105 ]. In terms of finance, the historical data is related to financial institutions to make high-stakes business decisions, which is mostly used for risk management, fraud prevention, credit allocation, customer analytics, personalized services, algorithmic trading, etc. Overall, data science methodologies can play a key role in the future generation business or finance industry, particularly in terms of business automation, intelligence, and smart decision-making and systems.
- Manufacturing or industrial data science: To compete in global production capability, quality, and cost, manufacturing industries have gone through many industrial revolutions [ 14 ]. The latest fourth industrial revolution, also known as Industry 4.0, is the emerging trend of automation and data exchange in manufacturing technology. Thus industrial data science, which is the study of industrial data to obtain insights that can typically lead to optimizing industrial applications, can play a vital role in such revolution. Manufacturing industries generate a large amount of data from various sources such as sensors, devices, networks, systems, and applications [ 6 , 68 ]. The main categories of industrial data include large-scale data devices, life-cycle production data, enterprise operation data, manufacturing value chain sources, and collaboration data from external sources [ 132 ]. The data needs to be processed, analyzed, and secured to help improve the system’s efficiency, safety, and scalability. Data science modeling thus can be used to maximize production, reduce costs and raise profits in manufacturing industries.
- Medical or health data science: Healthcare is one of the most notable fields where data science is making major improvements. Health data science involves the extrapolation of actionable insights from sets of patient data, typically collected from electronic health records. To help organizations, improve the quality of treatment, lower the cost of care, and improve the patient experience, data can be obtained from several sources, e.g., the electronic health record, billing claims, cost estimates, and patient satisfaction surveys, etc., to analyze. In reality, healthcare analytics using machine learning modeling can minimize medical costs, predict infectious outbreaks, prevent preventable diseases, and generally improve the quality of life [ 81 , 119 ]. Across the global population, the average human lifespan is growing, presenting new challenges to today’s methods of delivery of care. Thus health data science modeling can play a role in analyzing current and historical data to predict trends, improve services, and even better monitor the spread of diseases. Eventually, it may lead to new approaches to improve patient care, clinical expertise, diagnosis, and management.
- IoT data science: Internet of things (IoT) [ 9 ] is a revolutionary technical field that turns every electronic system into a smarter one and is therefore considered to be the big frontier that can enhance almost all activities in our lives. Machine learning has become a key technology for IoT applications because it uses expertise to identify patterns and generate models that help predict future behavior and events [ 112 ]. One of the IoT’s main fields of application is a smart city, which uses technology to improve city services and citizens’ living experiences. For example, using the relevant data, data science methods can be used for traffic prediction in smart cities, to estimate the total usage of energy of the citizens for a particular period. Deep learning-based models in data science can be built based on a large scale of IoT datasets [ 7 , 104 ]. Overall, data science and analytics approaches can aid modeling in a variety of IoT and smart city services, including smart governance, smart homes, education, connectivity, transportation, business, agriculture, health care, and industry, and many others.
- Cybersecurity data science: Cybersecurity, or the practice of defending networks, systems, hardware, and data from digital attacks, is one of the most important fields of Industry 4.0 [ 114 , 121 ]. Data science techniques, particularly machine learning, have become a crucial cybersecurity technology that continually learns to identify trends by analyzing data, better detecting malware in encrypted traffic, finding insider threats, predicting where bad neighborhoods are online, keeping people safe while surfing, or protecting information in the cloud by uncovering suspicious user activity [ 114 ]. For instance, machine learning and deep learning-based security modeling can be used to effectively detect various types of cyberattacks or anomalies [ 103 , 106 ]. To generate security policy rules, association rule learning can play a significant role to build rule-based systems [ 102 ]. Deep learning-based security models can perform better when utilizing the large scale of security datasets [ 140 ]. Thus data science modeling can enable professionals in cybersecurity to be more proactive in preventing threats and reacting in real-time to active attacks, through extracting actionable insights from the security datasets.
- Behavioral data science: Behavioral data is information produced as a result of activities, most commonly commercial behavior, performed on a variety of Internet-connected devices, such as a PC, tablet, or smartphones [ 112 ]. Websites, mobile applications, marketing automation systems, call centers, help desks, and billing systems, etc. are all common sources of behavioral data. Behavioral data is much more than just data, which is not static data [ 108 ]. Advanced analytics of these data including machine learning modeling can facilitate in several areas such as predicting future sales trends and product recommendations in e-commerce and retail; predicting usage trends, load, and user preferences in future releases in online gaming; determining how users use an application to predict future usage and preferences in application development; breaking users down into similar groups to gain a more focused understanding of their behavior in cohort analysis; detecting compromised credentials and insider threats by locating anomalous behavior, or making suggestions, etc. Overall, behavioral data science modeling typically enables to make the right offers to the right consumers at the right time on various common platforms such as e-commerce platforms, online games, web and mobile applications, and IoT. In social context, analyzing the behavioral data of human being using advanced analytics methods and the extracted insights from social data can be used for data-driven intelligent social services, which can be considered as social data science.
- Mobile data science: Today’s smart mobile phones are considered as “next-generation, multi-functional cell phones that facilitate data processing, as well as enhanced wireless connectivity” [ 146 ]. In our earlier paper [ 112 ], we have shown that users’ interest in “Mobile Phones” is more and more than other platforms like “Desktop Computer”, “Laptop Computer” or “Tablet Computer” in recent years. People use smartphones for a variety of activities, including e-mailing, instant messaging, online shopping, Internet surfing, entertainment, social media such as Facebook, Linkedin, and Twitter, and various IoT services such as smart cities, health, and transportation services, and many others. Intelligent apps are based on the extracted insight from the relevant datasets depending on apps characteristics, such as action-oriented, adaptive in nature, suggestive and decision-oriented, data-driven, context-awareness, and cross-platform operation [ 112 ]. As a result, mobile data science, which involves gathering a large amount of mobile data from various sources and analyzing it using machine learning techniques to discover useful insights or data-driven trends, can play an important role in the development of intelligent smartphone applications.
- Multimedia data science: Over the last few years, a big data revolution in multimedia management systems has resulted from the rapid and widespread use of multimedia data, such as image, audio, video, and text, as well as the ease of access and availability of multimedia sources. Currently, multimedia sharing websites, such as Yahoo Flickr, iCloud, and YouTube, and social networks such as Facebook, Instagram, and Twitter, are considered as valuable sources of multimedia big data [ 89 ]. People, particularly younger generations, spend a lot of time on the Internet and social networks to connect with others, exchange information, and create multimedia data, thanks to the advent of new technology and the advanced capabilities of smartphones and tablets. Multimedia analytics deals with the problem of effectively and efficiently manipulating, handling, mining, interpreting, and visualizing various forms of data to solve real-world problems. Text analysis, image or video processing, computer vision, audio or speech processing, and database management are among the solutions available for a range of applications including healthcare, education, entertainment, and mobile devices.
- Smart cities or urban data science: Today, more than half of the world’s population live in urban areas or cities [ 80 ] and considered as drivers or hubs of economic growth, wealth creation, well-being, and social activity [ 96 , 116 ]. In addition to cities, “Urban area” can refer to the surrounding areas such as towns, conurbations, or suburbs. Thus, a large amount of data documenting daily events, perceptions, thoughts, and emotions of citizens or people are recorded, that are loosely categorized into personal data, e.g., household, education, employment, health, immigration, crime, etc., proprietary data, e.g., banking, retail, online platforms data, etc., government data, e.g., citywide crime statistics, or government institutions, etc., Open and public data, e.g., data.gov, ordnance survey, and organic and crowdsourced data, e.g., user-generated web data, social media, Wikipedia, etc. [ 29 ]. The field of urban data science typically focuses on providing more effective solutions from a data-driven perspective, through extracting knowledge and actionable insights from such urban data. Advanced analytics of these data using machine learning techniques [ 105 ] can facilitate the efficient management of urban areas including real-time management, e.g., traffic flow management, evidence-based planning decisions which pertain to the longer-term strategic role of forecasting for urban planning, e.g., crime prevention, public safety, and security, or framing the future, e.g., political decision-making [ 29 ]. Overall, it can contribute to government and public planning, as well as relevant sectors including retail, financial services, mobility, health, policing, and utilities within a data-rich urban environment through data-driven smart decision-making and policies, which lead to smart cities and improve the quality of human life.
- Smart villages or rural data science: Rural areas or countryside are the opposite of urban areas, that include villages, hamlets, or agricultural areas. The field of rural data science typically focuses on making better decisions and providing more effective solutions that include protecting public safety, providing critical health services, agriculture, and fostering economic development from a data-driven perspective, through extracting knowledge and actionable insights from the collected rural data. Advanced analytics of rural data including machine learning [ 105 ] modeling can facilitate providing new opportunities for them to build insights and capacity to meet current needs and prepare for their futures. For instance, machine learning modeling [ 105 ] can help farmers to enhance their decisions to adopt sustainable agriculture utilizing the increasing amount of data captured by emerging technologies, e.g., the internet of things (IoT), mobile technologies and devices, etc. [ 1 , 51 , 52 ]. Thus, rural data science can play a very important role in the economic and social development of rural areas, through agriculture, business, self-employment, construction, banking, healthcare, governance, or other services, etc. that lead to smarter villages.
Overall, we can conclude that data science modeling can be used to help drive changes and improvements in almost every sector in our real-world life, where the relevant data is available to analyze. To gather the right data and extract useful knowledge or actionable insights from the data for making smart decisions is the key to data science modeling in any application domain. Based on our discussion on the above ten potential real-world application domains by taking into account data-driven smart computing and decision making, we can say that the prospects of data science and the role of data scientists are huge for the future world. The “Data Scientists” typically analyze information from multiple sources to better understand the data and business problems, and develop machine learning-based analytical modeling or algorithms, or data-driven tools, or solutions, focused on advanced analytics, which can make today’s computing process smarter, automated, and intelligent.
Challenges and Research Directions
Our study on data science and analytics, particularly data science modeling in “ Understanding data science modeling ”, advanced analytics methods and smart computing in “ Advanced analytics methods and smart computing ”, and real-world application areas in “ Real-world application domains ” open several research issues in the area of data-driven business solutions and eventual data products. Thus, in this section, we summarize and discuss the challenges faced and the potential research opportunities and future directions to build data-driven products.
- Understanding the real-world business problems and associated data including nature, e.g., what forms, type, size, labels, etc., is the first challenge in the data science modeling, discussed briefly in “ Understanding data science modeling ”. This is actually to identify, specify, represent and quantify the domain-specific business problems and data according to the requirements. For a data-driven effective business solution, there must be a well-defined workflow before beginning the actual data analysis work. Furthermore, gathering business data is difficult because data sources can be numerous and dynamic. As a result, gathering different forms of real-world data, such as structured, or unstructured, related to a specific business issue with legal access, which varies from application to application, is challenging. Moreover, data annotation, which is typically the process of categorization, tagging, or labeling of raw data, for the purpose of building data-driven models, is another challenging issue. Thus, the primary task is to conduct a more in-depth analysis of data collection and dynamic annotation methods. Therefore, understanding the business problem, as well as integrating and managing the raw data gathered for efficient data analysis, may be one of the most challenging aspects of working in the field of data science and analytics.
- The next challenge is the extraction of the relevant and accurate information from the collected data mentioned above. The main focus of data scientists is typically to disclose, describe, represent, and capture data-driven intelligence for actionable insights from data. However, the real-world data may contain many ambiguous values, missing values, outliers, and meaningless data [ 101 ]. The advanced analytics methods including machine and deep learning modeling, discussed in “ Advanced analytics methods and smart computing ”, highly impact the quality, and availability of the data. Thus understanding real-world business scenario and associated data, to whether, how, and why they are insufficient, missing, or problematic, then extend or redevelop the existing methods, such as large-scale hypothesis testing, learning inconsistency, and uncertainty, etc. to address the complexities in data and business problems is important. Therefore, developing new techniques to effectively pre-process the diverse data collected from multiple sources, according to their nature and characteristics could be another challenging task.
- Understanding and selecting the appropriate analytical methods to extract the useful insights for smart decision-making for a particular business problem is the main issue in the area of data science. The emphasis of advanced analytics is more on anticipating the use of data to detect patterns to determine what is likely to occur in the future. Basic analytics offer a description of data in general, while advanced analytics is a step forward in offering a deeper understanding of data and helping to granular data analysis. Thus, understanding the advanced analytics methods, especially machine and deep learning-based modeling is the key. The traditional learning techniques mentioned in “ Advanced analytics methods and smart computing ” may not be directly applicable for the expected outcome in many cases. For instance, in a rule-based system, the traditional association rule learning technique [ 4 ] may produce redundant rules from the data that makes the decision-making process complex and ineffective [ 113 ]. Thus, a scientific understanding of the learning algorithms, mathematical properties, how the techniques are robust or fragile to input data, is needed to understand. Therefore, a deeper understanding of the strengths and drawbacks of the existing machine and deep learning methods [ 38 , 105 ] to solve a particular business problem is needed, consequently to improve or optimize the learning algorithms according to the data characteristics, or to propose the new algorithm/techniques with higher accuracy becomes a significant challenging issue for the future generation data scientists.
- The traditional data-driven models or systems typically use a large amount of business data to generate data-driven decisions. In several application fields, however, the new trends are more likely to be interesting and useful for modeling and predicting the future than older ones. For example, smartphone user behavior modeling, IoT services, stock market forecasting, health or transport service, job market analysis, and other related areas where time-series and actual human interests or preferences are involved over time. Thus, rather than considering the traditional data analysis, the concept of RecencyMiner, i.e., recent pattern-based extracted insight or knowledge proposed in our earlier paper Sarker et al. [ 108 ] might be effective. Therefore, to propose the new techniques by taking into account the recent data patterns, and consequently to build a recency-based data-driven model for solving real-world problems, is another significant challenging issue in the area.
- The most crucial task for a data-driven smart system is to create a framework that supports data science modeling discussed in “ Understanding data science modeling ”. As a result, advanced analytical methods based on machine learning or deep learning techniques can be considered in such a system to make the framework capable of resolving the issues. Besides, incorporating contextual information such as temporal context, spatial context, social context, environmental context, etc. [ 100 ] can be used for building an adaptive, context-aware, and dynamic model or framework, depending on the problem domain. As a result, a well-designed data-driven framework, as well as experimental evaluation, is a very important direction to effectively solve a business problem in a particular domain, as well as a big challenge for the data scientists.
- In several important application areas such as autonomous cars, criminal justice, health care, recruitment, housing, management of the human resource, public safety, where decisions made by models, or AI agents, have a direct effect on human lives. As a result, there is growing concerned about whether these decisions can be trusted, to be right, reasonable, ethical, personalized, accurate, robust, and secure, particularly in the context of adversarial attacks [ 104 ]. If we can explain the result in a meaningful way, then the model can be better trusted by the end-user. For machine-learned models, new trust properties yield new trade-offs, such as privacy versus accuracy; robustness versus efficiency; fairness versus robustness. Therefore, incorporating trustworthy AI particularly, data-driven or machine learning modeling could be another challenging issue in the area.
In the above, we have summarized and discussed several challenges and the potential research opportunities and directions, within the scope of our study in the area of data science and advanced analytics. The data scientists in academia/industry and the researchers in the relevant area have the opportunity to contribute to each issue identified above and build effective data-driven models or systems, to make smart decisions in the corresponding business domains.
In this paper, we have presented a comprehensive view on data science including various types of advanced analytical methods that can be applied to enhance the intelligence and the capabilities of an application. We have also visualized the current popularity of data science and machine learning-based advanced analytical modeling and also differentiate these from the relevant terms used in the area, to make the position of this paper. A thorough study on the data science modeling with its various processing modules that are needed to extract the actionable insights from the data for a particular business problem and the eventual data product. Thus, according to our goal, we have briefly discussed how different data modules can play a significant role in a data-driven business solution through the data science process. For this, we have also summarized various types of advanced analytical methods and outcomes as well as machine learning modeling that are needed to solve the associated business problems. Thus, this study’s key contribution has been identified as the explanation of different advanced analytical methods and their applicability in various real-world data-driven applications areas including business, healthcare, cybersecurity, urban and rural data science, and so on by taking into account data-driven smart computing and decision making.
Finally, within the scope of our study, we have outlined and discussed the challenges we faced, as well as possible research opportunities and future directions. As a result, the challenges identified provide promising research opportunities in the field that can be explored with effective solutions to improve the data-driven model and systems. Overall, we conclude that our study of advanced analytical solutions based on data science and machine learning methods, leads in a positive direction and can be used as a reference guide for future research and applications in the field of data science and its real-world applications by both academia and industry professionals.
Declarations
The author declares no conflict of interest.
This article is part of the topical collection “Advances in Computational Approaches for Artificial Intelligence, Image Processing, IoT and Cloud Applications” guest edited by Bhanu Prakash K N and M. Shivakumar.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
IMAGES
VIDEO
COMMENTS
Research summary Analytic models are a powerful approach for developing theory, yet are often poorly understood in the strategy and organizations community. Our goal is to enhance the influence of the method by clarifying for consumers of modeling research how to understand and appreciate analytic modeling and use modeling results to enhance ...
For example, it can look into why the value of the Japanese Yen has decreased. This is so that an analytical study can consider "how" and "why" questions. Another example is that someone might conduct analytical research to identify a study's gap. It presents a fresh perspective on your data.
A model may be an analytical model or an intelligent model. A set of activities, largely sequential, that leads to the development of a validated model. The exercise of managerial and technical oversight in modeling. The degree to which the outputs of a model correspond to outcomes in the real world.
3 benefits of analytical modeling. It's hard to overstate the value of strong analytics. Mathematical analysis is useful at any scale and for almost every area of business management. 1. Data-driven decisions. The primary benefit of leveraging analytical modeling is the security of making data-driven decisions.
An analytical framework is, the way I see it, a model that helps explain how a certain type of analysis will be conducted. For example, in this paper, Franks and Cleaver develop an analytical framework that includes scholarship on poverty measurement to help us understand how water governance and poverty are interrelated.
Analytical Modeling: A Guide to Data-Driven Decision Making. July 30th, 2024. Analytical modeling is a comprehensive approach that employs mathematical models, statistical algorithms, and data analysis methods to understand, interpret, and predict outcomes based on historical data and known variables. At its core, it represents a quantitative ...
Design/methodology/approach The authors first develop a formal analytical model where expatriate managers are relatively more reliable and expensive while local managers are prone to job-hopping.
Summary. Often considered the "magic" of data science, the development of analytics models is the focus here. It begins with an introduction to analytics maturity, a definition of the term model, and an in-depth look at two competing perspectives on analytics modeling. These two perspectives—hypothesis-driven analytics and data-driven ...
21 Analytical Models. 21. Analytical Models. Marketing models consists of. Analytical Model: pure mathematical-based research. Empirical Model: data analysis. "A model is a representation of the most important elements of a perceived real-world system". Marketing model improves decision-making. Econometric models.
Analytical modeling, also known as analytics modeling, is a method used in data analysis and decision-making processes to gain insights, make predictions, and inform business strategies. It involves the use of mathematical and statistical models to understand and interpret data, identify patterns, and predict future outcomes based on historical ...
Based on this review, this chapter provides explanations for the analytical framework and the research methods used in our study. I will begin by investigating what kinds of research approach are available in the discipline of IT/IS and which is appropriate for the purpose of this study. My analysis will make clear that the survey approach is ...
6.2.5 Analytical models. Analytical model is a mathematical tool with a closed form solution, i.e., the solution to the equations describing any changes in the system is expressed as a mathematical analytic function. Feuchtwang and Infield [53] developed a closed form probabilistic model for estimating the expected delays caused by sea state ...
The best known project methodology for analytical processes is Cross Industrial Standard Processes for Data Mining (CRISP-DM) [1]. This methodology describes six phases that show an iterative approach to the development of analytical models. Although it describes the general approach to analytical model creation (Business understanding, Data ...
QDA Method #3: Discourse Analysis. Discourse is simply a fancy word for written or spoken language or debate. So, discourse analysis is all about analysing language within its social context. In other words, analysing language - such as a conversation, a speech, etc - within the culture and society it takes place.
Decision analysis is a systematic, quantitative, and transparent approach to making decisions under uncertainty. The fundamental tool of decision analysis is a decision-analytic model, most often a decision tree or a Markov model. A decision model provides a way to visualize the sequences of events that can occur following alternative decisions (or actions) in a logical framework, as well as ...
In the model presented here (Fig. 1), the sources of production are grouped into six top-tier, or alpha, variables: investments and ongoing funding; investigator experience and training; efficiency of the research environment; the research mix of novelty, incremental advancement, and confirmatory studies; analytic accuracy; and passion ...
The model developed on the basis of a systematic analysis process could be tested quantitatively with the themes aiding in the interpretation of results. Therefore, positivist-based methodologies could benefit from using mixed methods to develop a model at the first stage and then test that model at the second stage of research.
Research summary Analytic models are a powerful approach for developing theory, yet are often poorly understood in the strategy and organizations community. Our goal is to enhance the influence of the method by clarifying for consumers of modeling research how to understand and appreciate analytic modeling and use modeling results to enhance ...
An empirical model is the result of the number of experiments, in which a model type is selected, all necessary coefficients are calculated, and further tests are required to validate an empirical model. Compared with analytical model, empirical model requires the minimum effort, but the quality of this model is restricted to the particular ...
The review reveals that further research is essential to develop analytical models using EVA metrics to forecast project performance. It also suggests that DSS should be model driven, function as ...
The monograph belongs to the Series in Operations Research, and presents the method and methodology of Analytic Hierarchy Process (AHP)—one of the most popular tools of the practical multiple-criteria decision making (MCDM). AHP was proposed by Thomas Saaty in 1977, and from that time it has been developed and applied in numerous works.
Descriptive research classifies, describes, compares, and measures data. Meanwhile, analytical research focuses on cause and effect. For example, take numbers on the changing trade deficits between the United States and the rest of the world in 2015-2018. This is descriptive research.
Evidence relating to healthcare decisions often comes from more than one study. Decision analytical modelling can be used as a basis for economic evaluations in these situations. Economic evaluations are increasingly conducted alongside randomised controlled trials, providing researchers with individual patient data to estimate cost effectiveness.1 However, randomised trials do not always ...
A lack of deep analytical insight is a consequence not of software but of epistemology. Using examples informed by interpretive and critical approaches, the author demonstrates how NVivo can provide an effective tool for data management and analysis. ... a way to manufacture distance. It is a way to let the data of one's research project take ...
Overall, we conclude that our study of advanced analytical solutions based on data science and machine learning methods, leads in a positive direction and can be used as a reference guide for future research and applications in the field of data science and its real-world applications by both academia and industry professionals.